Introduction to Scikit Learn library
General Workflow

Step1: EDA (Exploratory data analysis)
Step2: Data preparation
- Data preprocessing & transformations
- Feature engineering
- (Feature selection)
- Missing values imputations
- Handling of outliers
Step3: Modeling
Depending on what you want to achieve:
- Split in Training and Test (randomly shuffled) (and/or validation set)
- Train a model on Training set, validate on test set (or validation set)
- model Hyperparameters tuning
- K-Fold cross validation or Bootstrap to check model predictions’stability / variance
- Go back to step 1 or 2 if not satisfied
Import du dataset
from sklearn.datasets import fetch_california_housing
california_housing = fetch_california_housing()
{ k:type(v) for k,v in california_housing.items() }
{'data': numpy.ndarray,
'target': numpy.ndarray,
'frame': NoneType,
'target_names': list,
'feature_names': list,
'DESCR': str}
print(california_housing.DESCR)
.. _california_housing_dataset:
California Housing dataset
--------------------------
**Data Set Characteristics:**
:Number of Instances: 20640
:Number of Attributes: 8 numeric, predictive attributes and the target
:Attribute Information:
- MedInc median income in block
- HouseAge median house age in block
- AveRooms average number of rooms
- AveBedrms average number of bedrooms
- Population block population
- AveOccup average house occupancy
- Latitude house block latitude
- Longitude house block longitude
:Missing Attribute Values: None
This dataset was obtained from the StatLib repository.
http://lib.stat.cmu.edu/datasets/
The target variable is the median house value for California districts.
This dataset was derived from the 1990 U.S. census, using one row per census
block group. A block group is the smallest geographical unit for which the U.S.
Census Bureau publishes sample data (a block group typically has a population
of 600 to 3,000 people).
It can be downloaded/loaded using the
:func:`sklearn.datasets.fetch_california_housing` function.
.. topic:: References
- Pace, R. Kelley and Ronald Barry, Sparse Spatial Autoregressions,
Statistics and Probability Letters, 33 (1997) 291-297
california_housing.target_names
['MedHouseVal']
discussion sur des critères discriminatoires : https://mail.python.org/pipermail/scikit-learn/2017-July/001683.html
Récupérer x et y
X = california_housing.data
y = california_housing.target
X.shape, y.shape
((20640, 8), (20640,))
Look at the data (i.e. EDA = Exploratory Data Analysis)
import pandas as pd
df = pd.DataFrame(california_housing.data,
columns=california_housing.feature_names)
df.head(5)
| MedInc | HouseAge | AveRooms | AveBedrms | Population | AveOccup | Latitude | Longitude | |
|---|---|---|---|---|---|---|---|---|
| 0 | 8.3252 | 41.0 | 6.984127 | 1.023810 | 322.0 | 2.555556 | 37.88 | -122.23 |
| 1 | 8.3014 | 21.0 | 6.238137 | 0.971880 | 2401.0 | 2.109842 | 37.86 | -122.22 |
| 2 | 7.2574 | 52.0 | 8.288136 | 1.073446 | 496.0 | 2.802260 | 37.85 | -122.24 |
| 3 | 5.6431 | 52.0 | 5.817352 | 1.073059 | 558.0 | 2.547945 | 37.85 | -122.25 |
| 4 | 3.8462 | 52.0 | 6.281853 | 1.081081 | 565.0 | 2.181467 | 37.85 | -122.25 |
df.dtypes
MedInc float64
HouseAge float64
AveRooms float64
AveBedrms float64
Population float64
AveOccup float64
Latitude float64
Longitude float64
dtype: object
df.describe().T
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| MedInc | 20640.0 | 3.870671 | 1.899822 | 0.499900 | 2.563400 | 3.534800 | 4.743250 | 15.000100 |
| HouseAge | 20640.0 | 28.639486 | 12.585558 | 1.000000 | 18.000000 | 29.000000 | 37.000000 | 52.000000 |
| AveRooms | 20640.0 | 5.429000 | 2.474173 | 0.846154 | 4.440716 | 5.229129 | 6.052381 | 141.909091 |
| AveBedrms | 20640.0 | 1.096675 | 0.473911 | 0.333333 | 1.006079 | 1.048780 | 1.099526 | 34.066667 |
| Population | 20640.0 | 1425.476744 | 1132.462122 | 3.000000 | 787.000000 | 1166.000000 | 1725.000000 | 35682.000000 |
| AveOccup | 20640.0 | 3.070655 | 10.386050 | 0.692308 | 2.429741 | 2.818116 | 3.282261 | 1243.333333 |
| Latitude | 20640.0 | 35.631861 | 2.135952 | 32.540000 | 33.930000 | 34.260000 | 37.710000 | 41.950000 |
| Longitude | 20640.0 | -119.569704 | 2.003532 | -124.350000 | -121.800000 | -118.490000 | -118.010000 | -114.310000 |
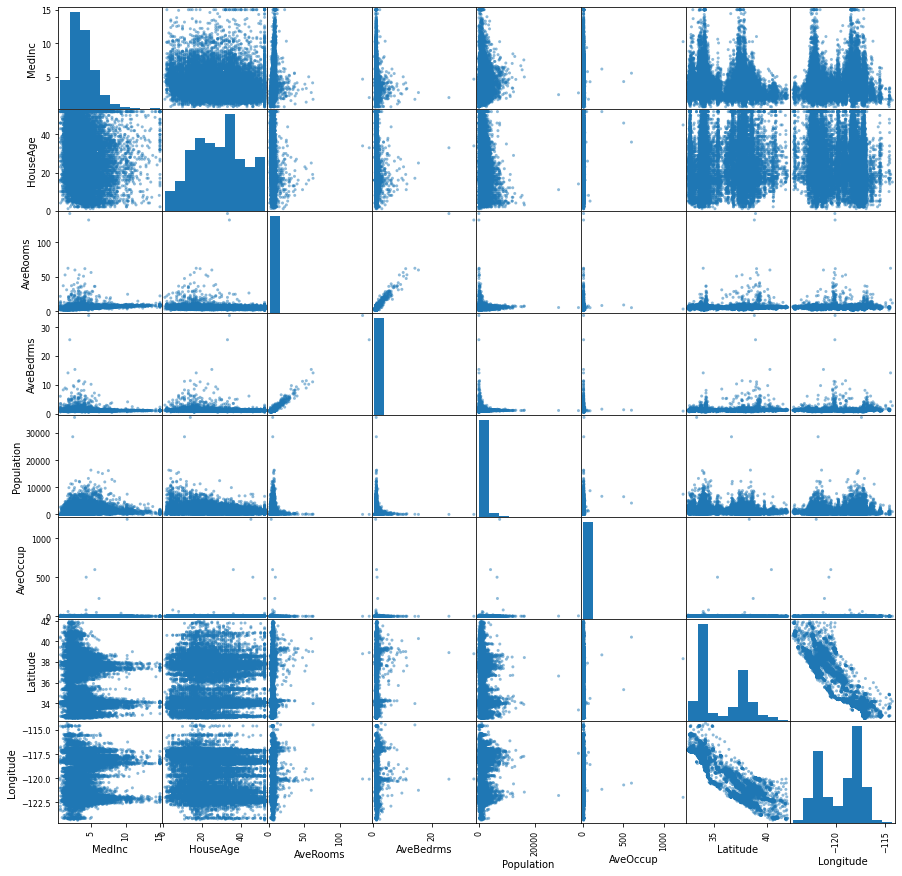
Let’s do a pairwise comparison between features
import matplotlib.pyplot as plt
infos = pd.plotting.scatter_matrix(df, figsize=(15,15))
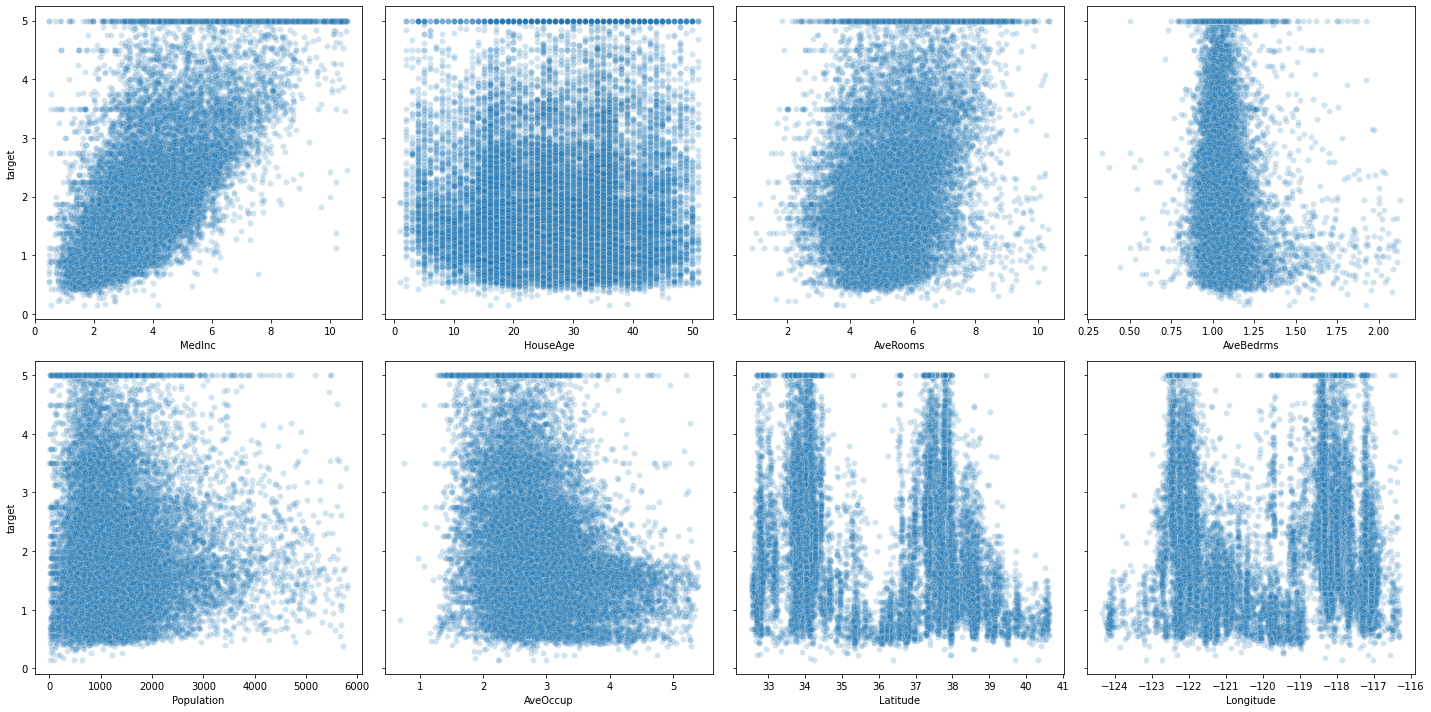
Let’s plot the target against each of those features
##def adding_plot_to_grid(fig, ncols):
## from itertools import count, cycle, repeat, chain, permutations
## import matplotlib.gridspec as gridspec
## import matplotlib.pyplot as plt
##
## # for ncols==3: 1 1 1 2 2 2 3 3 3
## seq_rows = chain.from_iterable(repeat(x, ncols) for x in count(start=1, step=1))
## seq_cols = cycle(range(1, ncols+1)) # for ncols==3: 1 2 3 1 2 3 1 2 3
##
## while True:
## current_nrows = next(seq_rows) # next row w.r.t. ncols
## current_col = next(seq_cols) # next col
## tmp = current_col if current_nrows==1 else ncols
## gs = gridspec.GridSpec(current_nrows, tmp)
##
## for i in range(len(fig.axes)):
## fig.axes[i].set_subplotspec(
## gs[ i // ncols, i % ncols])
## fig.tight_layout()
##
## # add a new subplot
## ax = fig.add_subplot(gs[current_nrows-1, current_col-1])
## ax.plot([1,2,3])
## fig.tight_layout()
##
## yield fig
## https://gist.github.com/LeoHuckvale/89683dc242f871c8e69b
## new_fig = pyplot.figure()
## gen = adding_plot_to_grid(new_fig, 3)
## %matplotlib inline
## fig = next(gen)
#in a Jupyter Notebook, the command fig, ax = plt.subplots()
#and a plot command need
# to be in the same
# cell in order for the plot to be rendered.
#from IPython.display import display
#display(fig)
import numpy as np
ncols, nrows = 4, 2
fig, axes = plt.subplots(figsize=(5*4,5*2), nrows=nrows, ncols=ncols, sharey=True)
for index, (name_col, col_series) in enumerate(df.iteritems()):
data = pd.DataFrame(np.vstack([np.array(col_series), y]).T, columns=['input', 'target'])
subset = data[data.input< np.percentile(data.input, 99)]
i, j = index // ncols, index % ncols
sns.scatterplot(x=subset.input,
y=subset.target,
ax=axes[i,j],
alpha=0.2)
axes[i,j].set_xlabel(name_col)
plt.tight_layout()
Preprocessing the data
Many variables can have different units (km vs mm), hence have different scales.
many estimators are designed with the assumption all features vary on comparable scales !
In particular metric-based and gradient-based estimators often assume approximately standardized data (centered features with unit variances), except decision tree estimators that are robust to scales
Standard deviation tells us about how the data is distributed around the mean.
Values from a standardized feature are expressed in unit variances.
- Scalers are affine transformers of a variable**.
a standardization scaler (implementend as scikit-learn StandardScaler):
for all $x_i$ in the realized observations of $X$
Normalization scalers (still for features) rescale the values into a range of $[\alpha,\beta]$, commonly $[0,1]$.
This can be useful if we need to have the values set in a positive range. Some normalizations rules can deal with outliers.
MinMaxScaler though is sensitive to outliers (max outliers are closer to 1, min are closer to 0, inliers are compressed in a tiny interval (included in the main one $[0,1]$).
An example of such, implemented in sklearn as MinMaxScaler
:
for all $x_i$ in the realized observations of $X$
Using StandardScaler or MinMaxScaler might depend on your use case? some guidance
Also using penalization techniques (especially ridge regression, we will see that later) impose constraints on the size of the coefficients, where large coefficients values might be more affected (large linear coefficients are often drawn from low valued variables since using high units’scale).
- You can use also non-linear transformations:
- Log transformation is an example of non-linear transformations that reduce the distance between high valued outliers with inliers, and respectively gives more emphasis to the low valued observations.
- Box-Cox is another example of non-linear parametrized transformation where an optimal parameter
lambdais found so to ultimately map an arbitriraly distributed set of observations to a normally distributed one (that can be later standardized). This also gives the effect of giving less importance to outliers since minimizing skewness. - QuantileTransformer is also non-linear transformer and greatly reduce the distance between outliers and inliers. Further explanation of the process can be found here
-
Finally, Normalizer normalizes a data vector (per sample transformation) (not the feature column) to a specified norm ($L_2$, $L_1$, etc.), e.g. $\frac{x}{ x _2}$ for $L_2$ norm.
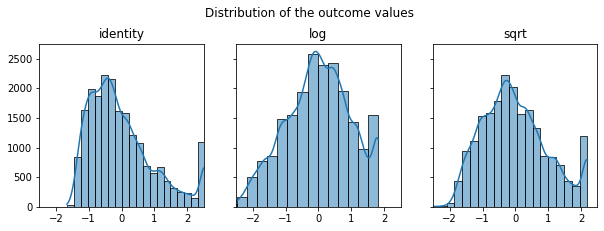
from sklearn.preprocessing import StandardScaler
import seaborn as sns
def identity(x):
return x
fig, axes = plt.subplots(1,3, figsize=(10,3), sharey=True)
plt.suptitle("Distribution of the outcome values", x=0.5, y=1.05)
for ax, func in zip(axes, [identity, np.log, np.sqrt]):
result = func(y.reshape(-1, 1))
result = StandardScaler().fit_transform(result)
sns.histplot(result[:,0], kde="true", ax=ax, bins=20)
ax.set_title(func.__name__)
ax.set(ylabel=None)
ax.set_xlim(-2.5,2.5)
sklearn.preprocessing.PowerTransformer:Apply a power transform featurewise to make data more Gaussian-like. This is useful for modeling issues related to heteroscedasticity (non-constant variance), or other situations where normality is desired.
for box-cox method: lambda parameter for minimizing skewness is estimated on each feature independently
applying it to the independent data or dependent one ?
The point is that you use this particular transformation to solve certain issue such as as heteroscedasticity of certain kind, and if this issue is not present in other variables then do not apply the transformation to them
Sometimes you even have to re-express both dependent and independent variables to attempt linearizing relationships (in the examlpe highlighted there: first log-ing the pressure and inverse-ing the temperature gives back the Clausus-Chapeyron relationship \(\color{red} {\ln{P}} = \frac{L}{R}\color{blue}{\frac{1}{T}} + c\)
$X$ is a feature: it is also mathematically considered as column vector.
Hence $X^T$ is the transposed used for a dot product ( shape of $X^T$ is $(1, p)$ )
df.HouseAge.head(4)
0 41.0
1 21.0
2 52.0
3 52.0
Name: HouseAge, dtype: float64
np.array(df.loc[:,["HouseAge"]])[:4] # [:4] is just to show the 4th first elements
array([[41.],
[21.],
[52.],
[52.]])
np.array(df.HouseAge).reshape(-1,1)[:4] # [:4] is just to show the 4th first elements
array([[41.],
[21.],
[52.],
[52.]])
from sklearn.preprocessing import PowerTransformer
pt_y = PowerTransformer(method="box-cox", standardize=True)
pt_y.fit(y.reshape(-1, 1))
print('lambda found: {}'.format(pt_y.lambdas_))
y_box_coxed = pt_y.transform(y.reshape(-1, 1))
lambda found: [0.12474766]
“RGB and RGBA are sequences of, respectively, 3 or 4 floats in the range 0-1.” https://matplotlib.org/3.3.2/api/colors_api.html
randcolor = lambda : list(np.random.random(size=3))
randcolor()
[0.6833369639833915, 0.8161914673207246, 0.3268027373629534]
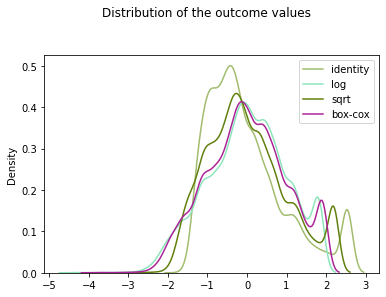
By putting all transformed values to the same scale (scaling)
from sklearn.preprocessing import StandardScaler
fig, ax = plt.subplots(1,1)
plt.suptitle("Distribution of the outcome values", x=0.5, y=1.05)
for func in [identity, np.log, np.sqrt]:
result = func(y).reshape(-1,1)
result = StandardScaler().fit_transform(result)
sns.kdeplot(result[:,0],
ax=ax,
color=randcolor() ,
label=func.__name__)
ax.set_label(func.__name__)
ax.set(ylabel=None)
sns.kdeplot(y_box_coxed[:,0], ax=ax, color=randcolor(), label="box-cox")
plt.legend()
<matplotlib.legend.Legend at 0x129ce8fa0>
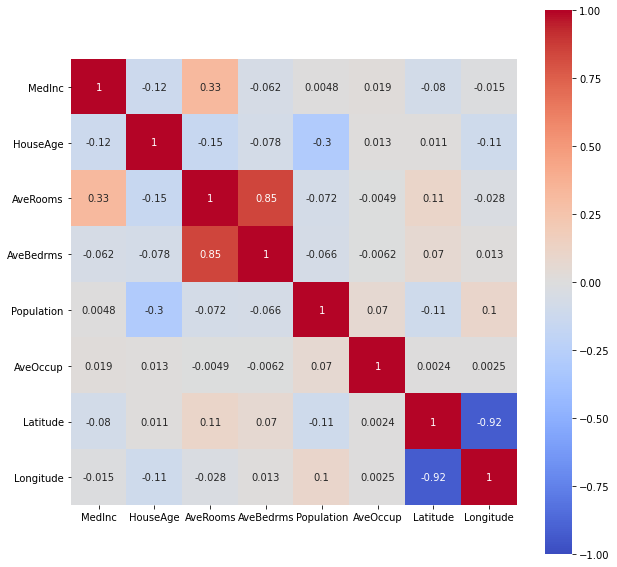
Look for correlations (linear, or by ranking)
plt.figure(figsize=(10,10))
sns.heatmap(df.corr("pearson"),
vmin=-1, vmax=1,
cmap='coolwarm',
annot=True,
square=True);
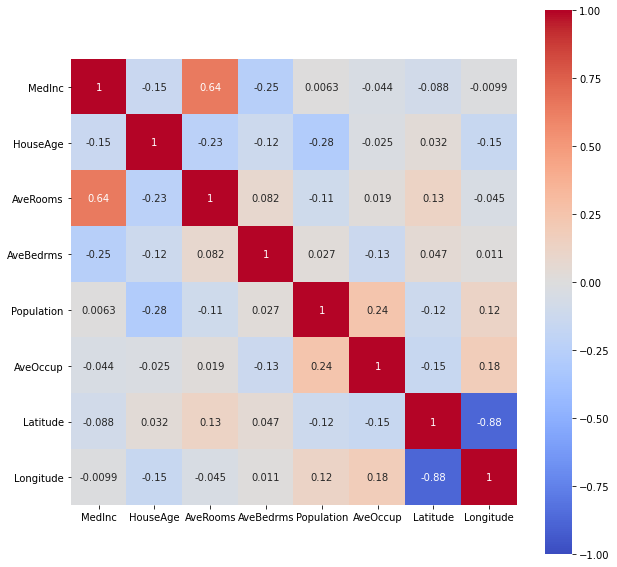
plt.figure(figsize=(10,10))
sns.heatmap(df.corr("spearman"),
vmin=-1, vmax=1,
cmap='coolwarm',
annot=True,
square=True);
Sklearn estimator object:
A common interface for all models (below is the general use case for supervised learning tasks, as we have seen an example above as with LinearRegression estimator)

the following dictionary will enable me to save the performances of the different built models trained on the training data and evaluated on the test set.
Choosing a performance metric
Metrics are quantitative measurements. The first, informal, definition of metric is consistent with the definition statistic, i.e. function of a sample <=> estimator
We could use the risk function MSE (mean squared error) to compare how bad in average (expected value) is each model at predicting values (using squared error loss), but in a regression case we could use a rather familiar statistic: the coefficient of determination $R^2$. It shows the proportion of the variance in the dependent variable that is predictable from the independent variable(s).
Closer to 1 is better, alhough it is important to check if there is no issues, like the **curse of dimensionality.
$R^2$ is useful because it is often easier to interpret since it doesn’t depend on the scale of the data but on the variance of $Y$ explained by the vars of $Xs$
$R^2$ coefficient of determination
In linear least squares multiple regression with an estimated intercept term, $R^2$ equals the square of the Pearson correlation coefficient between the observed $y$ and modeled (predicted) $\hat{y}$ data values of the dependent variable.
In a linear least squares regression with an intercept term and a single explanator, this is also equal to the squared Pearson correlation coefficient of the dependent variable $y$ and explanatory variable $x$.
How to derive $R^2$ ? We first need to define $SST$, $SSE$ and $RSS$:
\(SST = SSE + RSS\) (variance in the data expressed as some of squares distances around the mean) = variance explained by the model + remaining variance of the errors)
Be cautious with the litterature !
- Sometimes SSE means Sum of Square Errors (<=> Residual sum of squares)
- Sometimes while SSR means Sum or Square Regression (<=> variance explained by the regression model <=> ESS “Explained sum of squares”)
we seek to improve ESS, that is the variance explained by the model
\[R^2 = \frac{ESS}{TSS} = 1 - \frac{SSResiduals}{TotalSS}\]and \(MS(P)E = \frac{SSResiduals}{nbsamples}\)
$R^2$ and $MS(P)E$ are linked by the following formula:
\[MS(P)E(y,\hat{y}) = \frac{SSResiduals(y,\hat{y})}{Nsamples}\]For example, curse of dimensionality, results as in higher dimensional training data, as we can always fit perfectly a n-dimension hyperplane to n+1 data points into a n+1 dimension input space. The more dimensions the data has, the easier it is to find a hyperplane fitting the points in the training data, hence falsely resulting in a huge $R^2$
How to get p-values and a nice summary in Python as R summary(lm) ? https://stackoverflow.com/questions/27928275/find-p-value-significance-in-scikit-learn-linearregression
import numpy as np
from sklearn.linear_model import LinearRegression
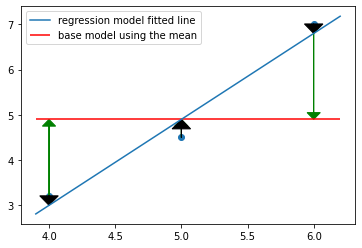
Linear regression for 3 points with 1 feature
lm = LinearRegression(fit_intercept=True)
x = np.array([[4], [5], [6]])
y = np.array([3.2, 4.5, 7])
lm.fit(X=x, y=y)
LinearRegression()
R2 = lm.score(X=x, y=y)
R2
0.967828418230563
lm.coef_
array([1.9])
lm.intercept_
-4.599999999999997
y - np.mean(y)
array([-1.7, -0.4, 2.1])
plt.scatter(x,y)
line_x_coords = np.linspace(3.9, 6.2, 3)
plt.plot(line_x_coords, lm.predict(line_x_coords[:, np.newaxis]), label="regression model fitted line")
plt.hlines(np.mean(y), xmin=min(line_x_coords), xmax=max(line_x_coords), color='red', label="base model using the mean")
for ix,iy in zip(x,y):
#plt.arrow(x, y, dx, dy)
# for arrow to the mean
plt.arrow(ix, iy, 0, -(iy-np.mean(y)), head_width=0.10, color="green", length_includes_head=True)
# for arrow to the fitted regression line
plt.arrow(ix, iy, 0, -float(iy-lm.predict(ix[:,np.newaxis])), head_width=0.14, color="black", length_includes_head=True)
plt.legend()
/Users/lucbertin/.pyenv/versions/3.8.4/lib/python3.8/site-packages/matplotlib/patches.py:1338: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
verts = np.dot(coords, M) + (x + dx, y + dy)
/Users/lucbertin/.pyenv/versions/3.8.4/lib/python3.8/site-packages/matplotlib/patches.py:1338: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
verts = np.dot(coords, M) + (x + dx, y + dy)
/Users/lucbertin/.pyenv/versions/3.8.4/lib/python3.8/site-packages/matplotlib/patches.py:1338: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
verts = np.dot(coords, M) + (x + dx, y + dy)
/Users/lucbertin/.pyenv/versions/3.8.4/lib/python3.8/site-packages/matplotlib/patches.py:1338: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
verts = np.dot(coords, M) + (x + dx, y + dy)
<matplotlib.legend.Legend at 0x13b8daf70>
SST = np.sum((y - np.mean(y))**2)
RSS = np.sum((y-lm.predict(x))**2)
RSS, SST
(0.24000000000000044, 7.459999999999999)
R2_train = 1 - RSS/SST
print(R2_train == R2)
R2_train
True
0.967828418230563
MSPE = RSS/len(x)
MSPE
0.08000000000000014
from sklearn.metrics import mean_squared_error
mean_squared_error(y, lm.predict(x))
0.08000000000000014
Linear regression for 3 points with 2 features
x = np.hstack([x, np.array([[3.2], [4.3], [1.2]])])
x
array([[4. , 3.2],
[5. , 4.3],
[6. , 1.2]])
lm = LinearRegression(fit_intercept=True)
lm.fit(X=x, y=y)
lm.score(X=x, y=y)
1.0
lm.coef_
array([ 1.61428571, -0.28571429])
x
array([[4. , 3.2],
[5. , 4.3],
[6. , 1.2]])
y
array([3.2, 4.5, 7. ])
fig = plt.figure(figsize=(10,10))
ax = fig.gca(projection='3d')
x1_coords = np.linspace(3, 8, 9)
x2_coords = np.linspace(0, 5, 7).T
#a, b = np.meshgrid(x1_coords, x2_coords, sparse=True)
#x_for_predicting = np.array(np.meshgrid(x1_coords, x2_coords)).T.reshape(-1, 2)
from sklearn.utils.extmath import cartesian
x_for_predicting = cartesian([x1_coords, x2_coords])
# predict y_pred
y_pred = lm.predict(x_for_predicting)
print( lm.score(x_for_predicting, y_pred))
# y_pred should be 2 dimensional respective to the inputs
# hence transformation : => coordinates grid => then T
y_pred = y_pred.reshape(len(x1_coords), len(x2_coords)).T
y_mean = np.tile(y.mean(), reps=(len(x1_coords), len(x2_coords))).T
ax = fig.add_subplot(projection='3d')
ax.scatter(x[:, 0], x[:, 1], y, marker='.', color='red', s=100)
ax.plot_surface(*np.meshgrid(x1_coords, x2_coords), y_pred, alpha=0.2)
ax.plot_surface(*np.meshgrid(x1_coords, x2_coords), y_mean, alpha=0.2, color='red')
1.0
<mpl_toolkits.mplot3d.art3d.Poly3DCollection at 0x13d56aa60>
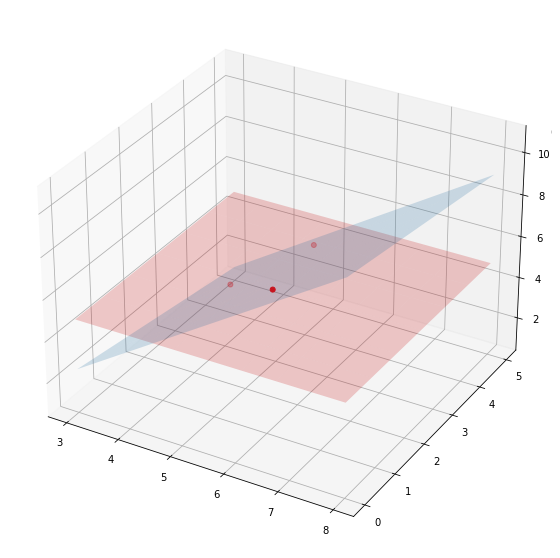
changing_nb_of_features = range(1,200,10)
xi_randoms_data_point = np.random.uniform(0, 10, size=(100, 200))
y_randoms_data_point = np.random.uniform(0, 10, size=(100,))
for i in changing_nb_of_features:
lm = LinearRegression()
xi_train, xi_test, yi_train, yi_test = \
train_test_split(xi_randoms_data_point[:, :i],
y_randoms_data_point,
random_state=1234)
lm.fit(xi_train, yi_train)
print("nb features: {}, score on test: {}\t, on train: {}".format(
i, round(lm.score(xi_test, yi_test),3), lm.score(xi_train, yi_train)))
nb features: 1, score on test: -0.017 , on train: 0.02229306156403521
nb features: 11, score on test: -0.314 , on train: 0.2009091438607158
nb features: 21, score on test: -0.669 , on train: 0.2596417503392714
nb features: 31, score on test: -1.299 , on train: 0.3921095720388704
nb features: 41, score on test: -1.742 , on train: 0.6088360328426371
nb features: 51, score on test: -2.376 , on train: 0.7442686557239004
nb features: 61, score on test: -4.179 , on train: 0.8214859039888791
nb features: 71, score on test: -75.92 , on train: 0.9518660637721018
nb features: 81, score on test: -11.977 , on train: 1.0
nb features: 91, score on test: -5.209 , on train: 1.0
nb features: 101, score on test: -3.804 , on train: 1.0
nb features: 111, score on test: -3.03 , on train: 1.0
nb features: 121, score on test: -1.153 , on train: 1.0
nb features: 131, score on test: -1.032 , on train: 1.0
nb features: 141, score on test: -0.993 , on train: 1.0
nb features: 151, score on test: -1.041 , on train: 1.0
nb features: 161, score on test: -1.047 , on train: 1.0
nb features: 171, score on test: -0.608 , on train: 1.0
nb features: 181, score on test: -0.637 , on train: 1.0
nb features: 191, score on test: -0.641 , on train: 1.0
$R^2$ compares the fit of the model with that of a horizontal straight line representing the mean of the data y (the null hypothesis) i.e. the outcome y is constant for all x. If the fit is worse, the $R^2$ can be negative.
making sense of dot product
That was an example of fitting a linear model using OLS method, making the assumption the outcome variable y is assumed to have a linear relationship with the feature(s) x(s)
You’ve maybe heard that the OLS estimator is BLUE, which stands for Best Linear Unbiased Estimator.
Let’s say the unobservable function is assumed to be of the form $f(x) = y + \beta_1{x_1} + \varepsilon$ where $\varepsilon$ is the error term.
(Here $\varepsilon$ is a catch-all variable even for the population model that may include among others: variables omitted from the model, unpredictable effects, measurement errors, and omitted variables, as there is always some kind of irreducible or unknown randomness error term (here too)).
Then: the OLS estimator is unbiased (the expected value from the $\hat{\beta}s$ among multiple subsets from the population is assumed to be the true $\beta_1$ of the population) and of minimum sampling variance (how jumpy each $\beta_1$ is from one data subset to the other) if the Gauss–Markov theorem’s assumptions are met:
- equal variances of the errors
- expected value of the errors is 0
- errors uncorrelated with the predictors
(Warning: as a result of applying the OLS method the residuals will be uncorrelated, but the error terms might not have been at first uncorrelated (violating the assumptions of linear regression))
from matplotlib import gridspec
import random
import seaborn as sns
from scipy import stats
grid = gridspec.GridSpec(1,2, width_ratios=[3,1])
fig_reg = plt.Figure(figsize=(12,9))
ax0 = fig_reg.add_subplot(grid[0])
x_lin = np.linspace(0, 10, 1000)
y_lin = np.random.normal(x, scale=0.8)
x_lin = x_lin[:,np.newaxis]
ax0.scatter(x_lin, y_lin, color="blue", label="population data", s=2)
ax0.plot(x_lin, LinearRegression().fit(x_lin, y_lin).predict(x_lin),
color='r', label='fitted regression line')
# saving "population true beta1" under assumption of a linear model:
beta = LinearRegression().fit(x_lin, y_lin).coef_
# picking up 10x10 points from the population, by simple sampling without replacement,
# and fitting a regression line for each of those subsets
# saving the betas_1 in dictionary
betas_1 = []
for subset_number, i_ in enumerate(np.random.randint(0, len(x_lin), size=(150,10))):
# linear regression on the subset
lm_subset = LinearRegression().fit(x_lin[i_,:], y_lin[i_])
# plot
ax0.plot(x_lin, lm_subset.predict(x_lin),
color='black', alpha=0.06, label='fitted regression line {}'.format(subset_number))
# saving the beta_1
betas_1.append(lm_subset.coef_[0])
ax1 = fig_reg.add_subplot(grid[1])
#sns.histplot(betas_1, ax=ax1)
#sns.distributions
sns.histplot(betas_1, kde = False, stat='density', ax=ax1)
x_coords = np.arange(-1,1,0.001)
y_normal_density = stats.norm.pdf(x_coords, loc=beta, scale=1/150)
#ax1.plot(x_coords, y_normal_density, 'r', lw=2)
fig_reg
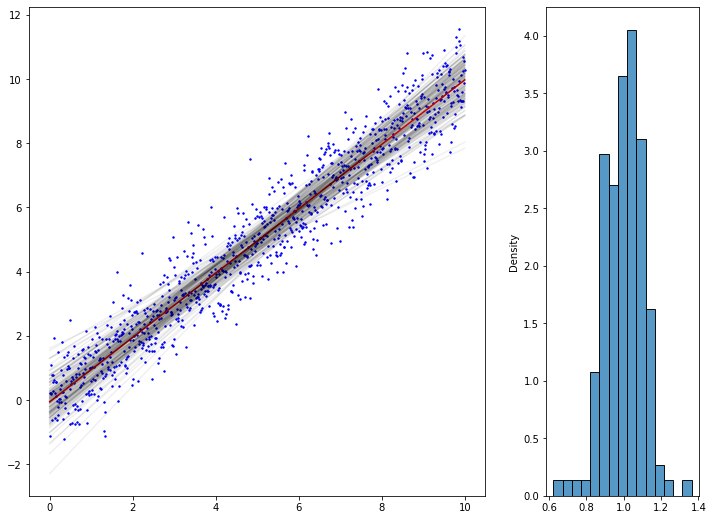
some other ressources from Stanford Uni
linear regression expressed as conditional means
Let’s take some other data example
x = np.linspace(0, 2*np.pi, 100)
y = np.random.normal(np.sin(x), scale=0.4)
%matplotlib inline
fig = plt.Figure()
ax = fig.add_subplot()
ax.scatter(x,y, color='b')
fig.tight_layout()
fig
<ipython-input-2172-57d06bb97c23>:4: MatplotlibDeprecationWarning: savefig() got unexpected keyword argument "dpi" which is no longer supported as of 3.3 and will become an error two minor releases later
fig.tight_layout()
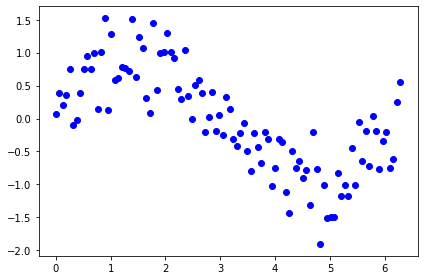
Is the underlying unobservable function linear ? it seems not…
Let’s say we know everything, that this function is the sinus
ax.plot(x, np.sin(x), color='r', label="true unobservable function")
fig.legend(loc='upper left', bbox_to_anchor=(1, 1)) #upper left is placed at x=1 y=1 on the figb
fig
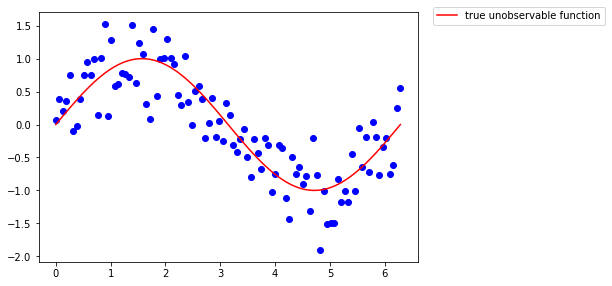
What if we tried to fit a linear model, assuming the unobservable function is linear in its coefficient (which is totally not the case) ?
lm = LinearRegression()
lm.fit(x[:, np.newaxis], y)
ax.plot(x, lm.predict(x[:, np.newaxis]), color='g', label='fitted regression line')
fig.legend()
fig
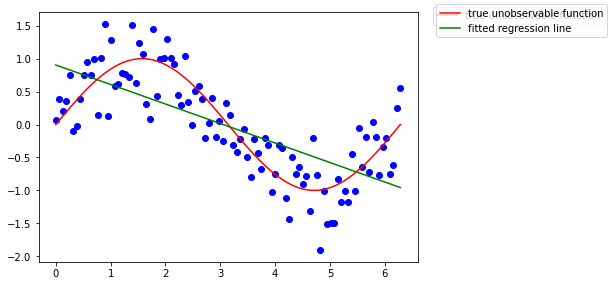
Recall the OLS estimator being BLUE? Well it is indeed, if the parameter model can be assumed as linear, that is, the assumptions of the Gauss-Markov model are met. Here the model estimates are clearly biased.
# grid and figure
grid = gridspec.GridSpec(1,2, width_ratios=[2,2])
fig_sin = plt.Figure(figsize=(11,7))
## PLOT 1
# the data
ax = fig_sin.add_subplot(grid[0])
ax.scatter(x, y, color="b", label="population data", s=2)
ax.plot(x, np.sin(x), color='r', label="true unobservable function")
# picking up 1000x2 points (indexes) from the population, by simple sampling without replacement,
# and fitting a regression line for each of those subsets
betas_1 = []
intercepts = []
tirages = np.random.randint(0, len(x), size=(5000,2))
for number, i_ in enumerate(tirages):
# linear regression on the subset
lm_subset = LinearRegression(fit_intercept=True).fit(x[i_, np.newaxis], y[i_])
# each 5 sampling (to not overload the graph)
if number % 5 == 0:
# plot
ax.plot(x, lm_subset.predict(x[:, np.newaxis]),
color='black', alpha=0.02)
# saving the beta_1
betas_1.append(lm_subset.coef_[0])
intercepts.append(lm_subset.intercept_)
ax.set_ylim(-2,2)
ax.set_xlim(0,2*np.pi)
ax.plot(x, np.mean(intercepts) + np.mean(betas_1)*x, color='g', label='"mean" of the fitted regression models')
## PLOT 2
ax = fig_sin.add_subplot(grid[1])
ax.scatter(x, y, color="b", label="population data", s=2)
ax.plot(x, np.sin(x), color='r', label="true unobservable function")
# simple "dummy" model (applied on all the data)
ax.plot(x, np.tile(np.mean(y), reps=(len(x),)))
print( np.mean(y) )
# picking up 1000x2 points (indexes) from the population, by simple sampling without replacement,
# and fitting a regression line for each of those subsets
means = []
tirages = np.random.randint(0, len(x), size=(1000,2))
for i_ in tirages:
# linear regression on the subset
dummy_model_y = np.tile(np.mean(y[i_]), reps=len(x))
# plot
ax.plot(x, dummy_model_y, color='black', alpha=0.02)
# save means
means.append(dummy_model_y[0])
ax.set_ylim(-2,2)
ax.set_xlim(0,2*np.pi)
ax.plot(x, np.tile(np.mean(means), reps=(len(x),)), color='g', label='"mean" of the fitted dummy models')
fig_sin
#fig_sin.legend(loc='upper left', bbox_to_anchor=(1, 1)) #upper left is placed at x=1 y=1 on the figb
-0.0023175740735309645
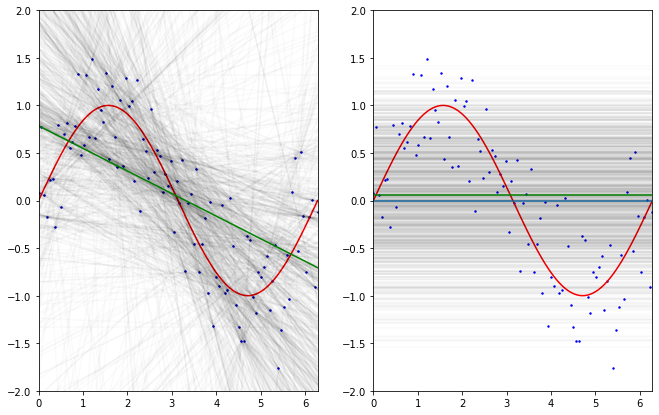
The above simulation is inspired from Caltech ML course by Yaser Abu-Mostafa (Lecture 8 - Bias-Variance Tradeoff)
What if we took a rather “dummy” model doing nothing more than computing the mean of 2 $y$ values for some given realizations of $X$: $x$ then:
- we see the dummy trained models (on 2 data points) are more stable in their “predictions” mainly due to the fact they are simpler models, not affected / taking into account some of the variations in the data.
- the regression models (trained on 2 data points) in average do perform better in trying to predict $y$ values, although the performance of the model are less stable from one another.
This is also called the Bias-Variance trade-off.
- The Bias can be seen as the error made by simplifying assumptions e.g. assuming there is a linear relationship where the unobservable function do have non linearities, there will be in average an error of mismatch as the estimated model will not be sensible to theses variations.
- The Variance of the model show how much the model, trained on some other data, (here with 2 data points each time) will vary around the mean.
The more complex the model gets, the more it will capture data tendencies, but this acquired sensibility will make the model more ‘variable’ in its parameters on different training sets. The less complex (with huge erroneous assumptions) the model is, the less sensible it is to capture the relations between the features and the output but it won’t be affected to different training sets.
Actually… When we compute the performance of both of these models using the MSPE. \(MSPE(L) = E[ ( g(x_i) - \hat{g}(x_i) )^2 ]\) (here i didn’t compare using the Y, but just with respect to the unobservable function, hence the latter equation in 7.3 is slightly different)
The former formula can be decomposed into 3 terms:

Having a high bias or a high variance, to the extreme, can be a real issue, we will see later why.
By the way the regression model is still very biased and we may be able to reduce both the variance and bias by using another family of model.
Let’s take a polynomial model instead (locally it will aproximate well, although it is a bad way of approximating the periodicity of the sine function).
To create this model, we are actually going to do some light feature engineering, in that case create new polynomial features from the original ones
from sklearn.preprocessing import PolynomialFeatures
poly3 = PolynomialFeatures(degree=3)
x_new = poly3.fit_transform(x[:, np.newaxis])
We hence created 4 features out of one, which hold the attributes: $constant, x, x2, x3$
x_new.shape
(100, 4)
x[:4]
array([0. , 0.06346652, 0.12693304, 0.19039955])
x[:4]**2
array([0. , 0.004028 , 0.016112 , 0.03625199])
x[:4]**3
array([0. , 0.00025564, 0.00204514, 0.00690236])
x_new[:4, :]
array([[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00],
[1.00000000e+00, 6.34665183e-02, 4.02799894e-03, 2.55643068e-04],
[1.00000000e+00, 1.26933037e-01, 1.61119958e-02, 2.04514455e-03],
[1.00000000e+00, 1.90399555e-01, 3.62519905e-02, 6.90236284e-03]])
But we will now still use the linear regression, using those new features !
Indeed the relation is still linear in its coefficient $\beta$s, although not with respect to its features.
Be aware though that this can be affected by the curse of dimensionality, as the number of new features grows much faster than linearly with the growth of degree of polynomial.
Let’s assume then the true relationship (at least locally) is \(y = \beta_0 + \beta_1 x + \beta_2 x^2 + \beta_3 x^3\)
lm_poly = LinearRegression().fit(x_new, y) # x_new is already 2D data
ax = fig.gca()
ax.plot(x, lm_poly.predict(x_new), color='purple', label='regression on polynomial features degree 3')
fig.legend()
fig
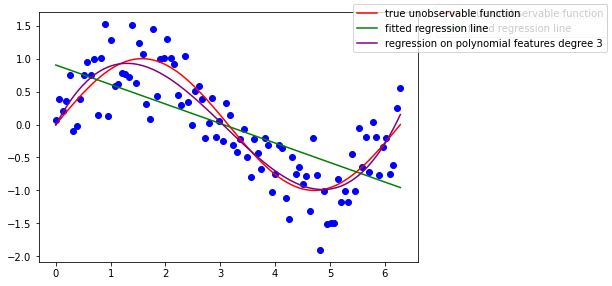
We get back somehow the Taylor expansion coeficients locally at the order 3
\[sin(x) = x - \frac{x^3}{3!} + \frac{x^5}{5!} - ...\]lm_poly.coef_ # first is the intercept due to the poly transform
array([ 0. , 1.6268111 , -0.78227311, 0.08384429])
By the way, as highlighted in the sklearn docs, when you have multiple data processing and modelisation you can chain all those functions / pipe them using the Pipeline object
from sklearn.pipeline import Pipeline
# Intermediate steps of the pipeline must be 'transforms', that is, they
# must implement fit and transform methods.
# The final estimator only needs to implement fit.
pipeline = Pipeline([
('poly', PolynomialFeatures()),
('linear', LinearRegression())
])
# The purpose of the pipeline is to assemble several steps that can be
# cross-validated together while setting different parameters.
# For this, it enables setting parameters of the various steps using their
# names and the parameter name separated by a '__',
pipeline.set_params(poly__degree=5)
# Fit all the transforms one after the other and transform the
# data, then fit the transformed data using the final estimator
pipeline.fit(x[:, np.newaxis], y)
Pipeline(steps=[('poly', PolynomialFeatures(degree=5)),
('linear', LinearRegression())])
ax = fig.gca()
ax.plot(x, pipeline.predict(x[:,np.newaxis]), color='orange', label='regression on polynomial features degree 5 (using pipeline)')
fig.legend()
fig
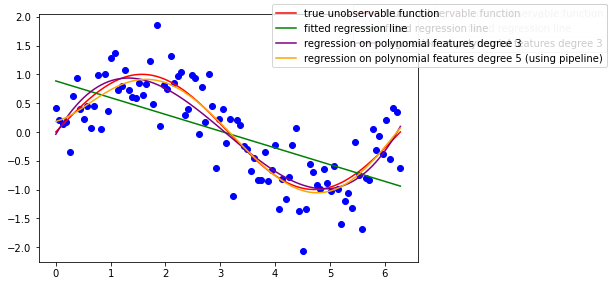
So far these are the features that we used to fit a linear model:
We started doing feature engineering, why not adding other features such as:
- sqrt(x)
- exp(x)
- log(x+1)
- 1/(x+1)
- cos(x)
- sin(x) for all types of “x” (x, x2, x3)
from sklearn.base import BaseEstimator, TransformerMixin
class AddFeatures(BaseEstimator, TransformerMixin):
def __init__(self, where_x, functions=None):
self.functions = functions
self.where_x = where_x
def fit(self, X, y):
return self
def transform(self, X):
# .T to iterate over the cols of the array
# vstack to stack vertically row by row
# then .T to go back to the initial shape
# not taking the intercept (index 0)
#if self.intercept_exist:
# start = 1
# x_ = X[:,start:]
#else:
# start = 0
# x_ = X
x_ = X[:, [self.where_x]].copy()
self.funcs_applied = ["{}".format(func.__name__) for func in self.functions]
cols = np.hstack([func(x_) for func in self.functions])
return np.hstack([X, cols])
class BetterPipeline(Pipeline):
""" Since pipeline.transform does work only when all estimators are transformers of the data,
and mostly i'm fitting a model as last estimator, i prefer creating a just_transform method for that"""
def just_transforms(self, X):
"""Applies all transforms to the data, without applying last
estimator.
Parameters
----------
X : iterable
Data to predict on. Must fulfill input requirements of first step of
the pipeline.
"""
Xt = X
for name, transform in self.steps[:-1]:
Xt = transform.transform(Xt)
return Xt
funcs = [np.sin, np.cos, np.exp]
pipeline = BetterPipeline([
('adding_features', AddFeatures(where_x=0)),
('poly', PolynomialFeatures(degree=2, interaction_only=True)),
('linear_reg', LinearRegression(fit_intercept=False))
])
pipeline.set_params(adding_features__functions=funcs)
pipeline.fit(x[:, np.newaxis], y)
BetterPipeline(steps=[('adding_features',
AddFeatures(functions=[<ufunc 'sin'>, <ufunc 'cos'>,
<ufunc 'exp'>],
where_x=0)),
('poly', PolynomialFeatures(interaction_only=True)),
('linear_reg', LinearRegression(fit_intercept=False))])
let’s build again a linear model out of them:
pipeline.named_steps.adding_features.funcs_applied
['sin', 'cos', 'exp']
x[:,np.newaxis][:4]
array([[0. ],
[0.06346652],
[0.12693304],
[0.19039955]])
pipeline.just_transforms(x[:, np.newaxis])[:4].shape
# cst, x1, x2, x3, f1(x1), f2(x1),..., f5(x1), ..., f5(x3)
(4, 11)
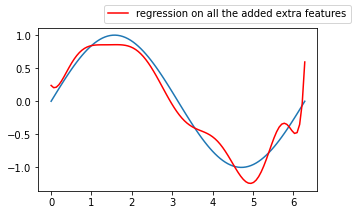
fig = plt.Figure()
ax = fig.gca()
ax.plot(x, np.sin(x))
ax.plot(x, pipeline.predict(x[:, np.newaxis]), color='r',
label='regression on all the added extra features')
fig.legend()
fig.set_size_inches(5,3)
fig
params = dict(zip(["x0", "x1", "x2", "x3"], ["x"]+pipeline.named_steps.adding_features.funcs_applied))
list_of_features = []
for feature in pipeline.named_steps.poly.get_feature_names():
for el in params:
feature = feature.replace(el, params.get(el))
list_of_features.append(feature)
params
{'x0': 'x', 'x1': 'sin', 'x2': 'cos', 'x3': 'exp'}
results = dict(zip(list_of_features, pipeline.named_steps.linear_reg.coef_))
results
{'1': 237.5537660813595,
'x': -42.176913529594344,
'sin': 61.83606673496575,
'cos': -218.42791323834305,
'exp': -20.44189022468796,
'x sin': -92.94656937907925,
'x cos': 11.742334620526949,
'x exp': 3.0572435486793452,
'sin cos': -14.204239122902498,
'sin exp': -2.296926010011112,
'cos exp': 1.5551590338739443}
sns.barplot(list(results.keys()), list(results.values()))
plt.xticks(rotation=90)
/Users/lucbertin/.pyenv/versions/3.8.4/lib/python3.8/site-packages/seaborn/_decorators.py:36: FutureWarning: Pass the following variables as keyword args: x, y. From version 0.12, the only valid positional argument will be `data`, and passing other arguments without an explicit keyword will result in an error or misinterpretation.
warnings.warn(
(array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]),
[Text(0, 0, '1'),
Text(1, 0, 'x'),
Text(2, 0, 'sin'),
Text(3, 0, 'cos'),
Text(4, 0, 'exp'),
Text(5, 0, 'x sin'),
Text(6, 0, 'x cos'),
Text(7, 0, 'x exp'),
Text(8, 0, 'sin cos'),
Text(9, 0, 'sin exp'),
Text(10, 0, 'cos exp')])
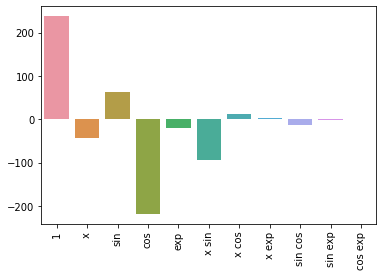
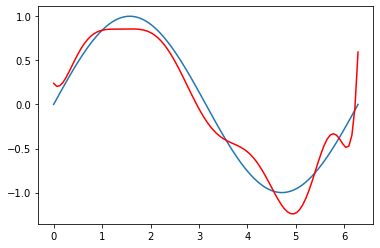
plt.plot(x, np.sin(x))
plt.plot(x, 237.5537660813595
-42.176913529594344*x
+61.83606673496575*np.sin(x)
-218.42791323834305*np.cos(x)
-20.44189022468796*np.exp(x)
-92.94656937907925*np.sin(x)*x
+11.742334620526949*np.cos(x)*x
+3.0572435486793452*np.exp(x)*x
-14.204239122902498*np.sin(x)*np.cos(x)
-2.296926010011112*np.sin(x)*np.exp(x)
+1.5551590338739443*np.cos(x)*np.exp(x)
, color='r',
label='regression on all the added extra features')
[<matplotlib.lines.Line2D at 0x181120e80>]
def inverse(x):
return 1/(1+x)
def log_and_1(x):
return np.log(1+x)
funcs = [np.sin, np.cos, np.exp, inverse, log_and_1, np.sqrt]
pipeline.set_params(adding_features__functions=funcs,
poly__degree=4, poly__interaction_only=False)
pipeline.fit(x[:, np.newaxis], y)
params = dict(zip(["x0", "x1", "x2", "x3", "x4", "x5"], ["x"]+pipeline.named_steps.adding_features.funcs_applied))
list_of_features = []
for feature in pipeline.named_steps.poly.get_feature_names():
for el in params:
feature = feature.replace(el, params.get(el))
list_of_features.append(feature)
fig = plt.Figure()
ax = fig.gca()
ax.plot(x, np.sin(x))
ax.plot(x, pipeline.predict(x[:, np.newaxis]), color='r',
label='regression on all the added extra features')
ax.scatter(x, y)
fig.legend()
fig.set_size_inches(5,4)
fig
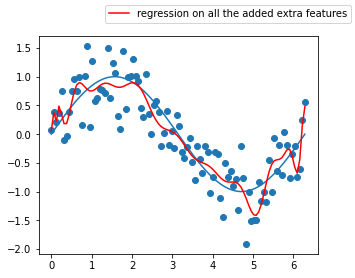
Does these models look really better than the previous 3 degree polynomial one without interaction terms ? 🤔
This model seems so complex that it has actually started learning the noise in the training data, this is a great example where the bias is low, but the variance is very high, we call this phenomenon overfitting.
The inverse is underfitting (“immutable” model due to its simplicity built from exagerated reductive assumptions)
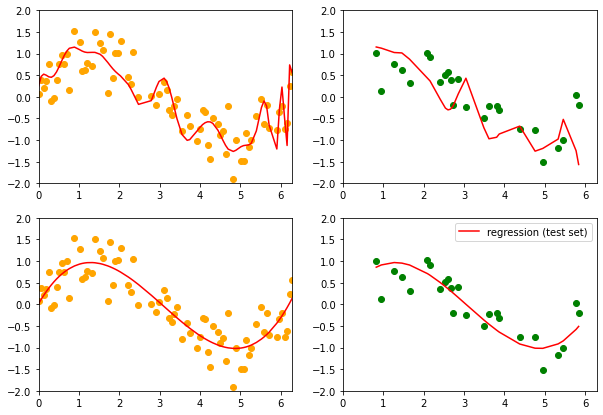
To assess overfitting, one can use cross-validation techniques !
By splitting the dataset into training and test set, you can validate whether your model will generalize well to unseen data. Hence if the model has started learning the noise in the training data, you should expect that:
\[MSPE(training_{data}) < MSPE(test_{data})\]# set indexes for the training data (we chose 75% of the data for training, the rest as test set)
train_index = list(set(np.random.choice(len(x_after_feature_engineering), size=75, replace=False)))
test_index = list(set(range(100)) - set(train_index))
# the training
X_train, y_train = x_after_feature_engineering[train_index], y[train_index]
X_test, y_test = x_after_feature_engineering[test_index], y[test_index]
# train the big pipeline on the training set
pipeline.fit(X_train, y_train)
# compute MSPE for both
MSPE_train = mean_squared_error(pipeline.predict(X_train), y_train)
MSPE_test = mean_squared_error(pipeline.predict(X_test), y_test)
print("MSE train/test with the pipeline {}, {}".format(MSPE_train, MSPE_test))
# just a linear model with regression on poly features degree 3
poly = PolynomialFeatures(degree=3, include_bias=False)
x2 = poly.fit_transform(x[:, np.newaxis])
lm = LinearRegression().fit(x2[train_index], y[train_index])
# compute MSPE for both
MSPE_train = mean_squared_error(lm.predict(x2[train_index]), y_train)
MSPE_test = mean_squared_error(lm.predict(x2[test_index]), y_test)
print("MSE train/test with poly and linear regression {}, {}".format(MSPE_train, MSPE_test))
# show predictions on training and test data
fig, axes = plt.subplots(figsize=(10,7), ncols=2, nrows=2)
#axes[0].plot(x[train_index], np.sin(x[train_index]))
#axes[1].plot(x[test_index], np.sin(x[test_index]))
axes[0,0].scatter(x[train_index], y[train_index], color='orange')
axes[0,1].scatter(x[test_index], y[test_index], color='g')
axes[0,0].plot(x[train_index], pipeline.predict(X_train), color='r',
label='regression (train set)')
axes[0,1].plot(x[test_index], pipeline.predict(X_test), color='r',
label='regression (test set)')
axes[1,0].scatter(x[train_index], y[train_index], color='orange')
axes[1,1].scatter(x[test_index], y[test_index], color='g')
axes[1,0].plot(x[train_index], lm.predict(x2[train_index]), color='r',
label='regression (train set)')
axes[1,1].plot(x[test_index], lm.predict(x2[test_index]), color='r',
label='regression (test set)')
for ax in axes.flatten():
ax.set_xlim(0, 2*np.pi)
ax.set_ylim(-2, 2)
plt.legend()
plt.show()
MSE train/test with the pipeline 0.16079231932432714, 0.4153474547263636
MSE train/test with poly and linear regression 0.14298871828570994, 0.11952029155922295

How to make our model simpler, that is introduce more bias to lower the variance, when we have no idea of which of the coefficients should be discarded from the analysis ? (also when we can’t simply check p-values from a regression analysis because 1. they could be useless or misleading if the assumptions are not met, 2. one could use something else than a regression model): regularization !
(Remarque : A ce stade, nous devrions réaliser une sélection de variables (approche fondée sur le F-partiel ou s’appuyant sur l’optimisation des critères AIC / BIC par exemple) avant de procéder à la prédiction. Nous choisissons néanmoins de les conserver toutes dans ce tutoriel pour simplifier la démarche mais: The interpretation of a regression coefficient is that it represents the mean change in the dependent variable for each 1 unit change in an independent variable when you hold all of the other independent variables constant. That last portion is crucial for our further discussion about multicollinearity The idea is that you can change the value of one independent variable and not the others. However, when independent variables are correlated, it indicates that changes in one variable are associated with shifts in another variable. ) prediction given by OLS model should not be affected by multicolinearity, as overall effect of predictor variables is not hurt by presence of multicolinearity. It is interpretation of effect of individual predictor variables that are not reliable when multicolinearity is present
Regularization


x_after_feature_engineering = pipeline.just_transforms(x[:, np.newaxis])
xnz = StandardScaler().fit_transform(x_after_feature_engineering)
LinearRegression(fit_intercept=False).fit(xnz,y).coef_
array([ 0. , -77.2693271 , 43.50552929, -155.20682759,
-2625.68503844, -213.7164138 , 30.97508782, 2377.71869959,
-4.99678403, -143.01826552, 199.14764254])
from sklearn.linear_model import Lasso
regLasso1 = Lasso(fit_intercept=False, normalize=False, alpha=1)
regLasso1.get_params()
{'alpha': 1,
'copy_X': True,
'fit_intercept': False,
'max_iter': 1000,
'normalize': False,
'positive': False,
'precompute': False,
'random_state': None,
'selection': 'cyclic',
'tol': 0.0001,
'warm_start': False}
regLasso1.fit(x_after_feature_engineering, y)
regLasso1.coef_
array([ 0. , 0. , 0. , 0. , 0. ,
0. , 0. , -0.00056407, -0. , 0.00531828,
0.00429535])
regLasso2 = Lasso(fit_intercept=False, normalize=False,
alpha=0.00001)
regLasso2.fit(x_after_feature_engineering, y)
regLasso2.coef_
/Users/lucbertin/.pyenv/versions/3.8.4/lib/python3.8/site-packages/sklearn/linear_model/_coordinate_descent.py:529: ConvergenceWarning: Objective did not converge. You might want to increase the number of iterations. Duality gap: 6.725850754163225, tolerance: 0.00597784722657327
model = cd_fast.enet_coordinate_descent(
array([ 2.03166073e-01, -1.01604804e-01, 7.44627444e-01, -8.19587125e-02,
1.30652915e-03, 6.73399699e-02, 1.84634132e-02, 5.93093705e-05,
2.31573136e-01, -1.14008641e-03, -7.32445409e-04])
oups… seems alpha=1.0 is too big and the regularization too high!
my_alphas = np.append(np.linspace(0.01, 0.25, 100), np.linspace(0.25, 0.8, 50))
# lasso_path() produce the esimated coefs_ for different values of alphas:
from sklearn.linear_model import lasso_path
alpha_for_path, coefs_lasso, _ = lasso_path(x_after_feature_engineering, y, alphas=my_alphas,
tol=0.8, normalize=False, fit_intercept=False)
coefs_lasso.shape
(11, 150)
import matplotlib.cm as cm
colors = cm.rainbow(np.linspace(0,1,16))
fig = plt.Figure(figsize=(12,5))
ax = fig.gca()
for i in range(coefs_lasso.shape[0]):
ax.plot(alpha_for_path, coefs_lasso[i,:], c=colors[i], label=list_of_features[i])
ax.set_xscale('log')
ax.set_xlabel('Alpha')
ax.set_ylabel('Coefficients')
ax.set_title('Lasso path')
fig.legend()
fig
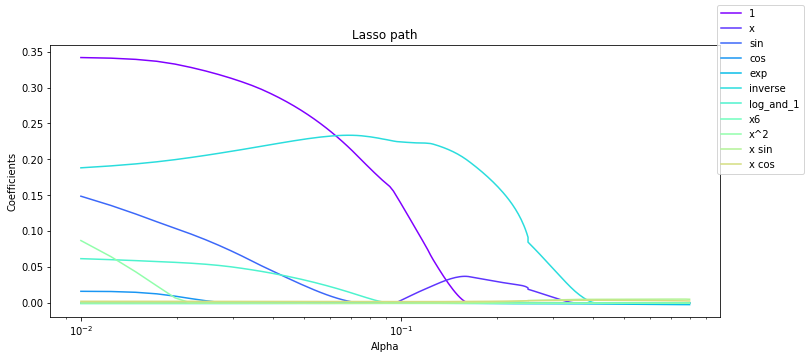
Going back to our example
Divide in train - test sets
X = california_housing.data
y = california_housing.target
X.shape, y.shape
((20640, 8), (20640,))
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = \
train_test_split(X, y, random_state=1234)
X_train.shape, X_test.shape, y_train.shape, y_test.shape
[tuple_[0]/X.shape[0] for tuple_ in (X_train.shape, X_test.shape, y_train.shape, y_test.shape)]
the return of the standard Scaler
performances = dict()
scaler = StandardScaler().fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
linear_model = LinearRegression(fit_intercept=False, normalize=True)
linear_model.fit(X_train, y_train)
LinearRegression(fit_intercept=False, normalize=True)
linear_model.score(X_test, y_test)
-2.630399387268966
## Predictions against True values
%matplotlib inline
import matplotlib.pyplot as plt
plt.scatter(x=y_test, y=linear_model.predict(X_test))
<matplotlib.collections.PathCollection at 0x139fbd940>
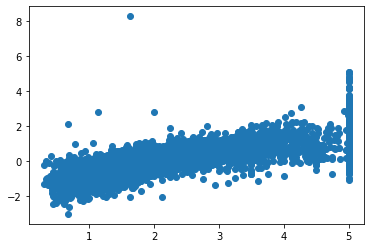
linear_model.coef_
array([ 4.40921745e-01, 9.73014997e-03, -1.16418460e-01, 7.21082459e-01,
-4.13919790e-06, -3.85206103e-03, -4.14706815e-01, -4.29215601e-01])
performances[linear_model] = linear_model.score(X_test, y_test)
But train/test split does have its dangers — what if the split we make isn’t random?
Instead of algo1 we can use directly LinearRegression() as it will fit it anyway on the different splits
performances
{LinearRegression(): 0.5951538103198971}
Ridge and Lasso regressions
This is an example of hyperparametrized model. The hyperparameter is a regularization parameter here.
For greater values of $\alpha$, the $\beta s$ will get shrunk towards 0 as we seek to find the $\beta s$ which minimize the overall equation where the 2nd part is getting more and more weight due to $\alpha$
as $\alpha$ increases, the b
Mettre tout ceci sous forme d’une fonction
def get_score(algorithme, X_train, X_test, y_train, y_test, display_graph=False, display_options=True):
if display_options:
print("fitting :\n"+ str(algorithme))
print("X_train:{} , X_test:{} , y_train:{} , y_test:{}".format(X_train.shape, X_test.shape, y_train.shape, y_test.shape))
modele = algorithme.fit(X_train, y_train)
score = modele.score(X_test, y_test)
if display_graph:
import matplotlib.pyplot as plt
plt.scatter(x=y_test, y=algorithme.predict(X_test)) ## Predictions against True values
return score
get_score(LinearRegression(), *train_test_split(X, y, random_state=1234))
fitting :
LinearRegression()
X_train:(15480, 8) , X_test:(5160, 8) , y_train:(15480,) , y_test:(5160,)
0.5951538103198971
Avons-nous besoin de Standardizer les valeurs ?
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler().fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
pd.DataFrame(X_train)
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|---|
| 0 | -0.354739 | -1.884591 | 0.088138 | -0.087609 | 1.914435 | 0.044927 | -0.494293 | 0.815921 |
| 1 | 0.127656 | 0.749561 | 0.036452 | -0.287105 | -0.177434 | -0.061717 | 1.174861 | -0.858112 |
| 2 | 1.469169 | -0.527604 | 0.916167 | -0.238028 | 0.439605 | 0.014134 | -0.812227 | 0.850901 |
| 3 | 0.050005 | 0.589915 | -0.060592 | -0.358913 | -0.727597 | -0.049610 | 0.969139 | -1.287864 |
| 4 | -0.170006 | -1.964414 | 0.360906 | 0.530414 | 0.049943 | -0.056194 | 0.347298 | -0.043583 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 15475 | 0.587404 | -0.607427 | -1.094179 | -0.558997 | -1.242094 | -0.115526 | -0.873008 | 0.666007 |
| 15476 | -0.585187 | -1.166186 | 0.166960 | 0.190634 | -0.239851 | -0.059006 | 0.824199 | -0.143525 |
| 15477 | 0.174257 | 0.350447 | -0.185899 | 0.140665 | -0.311185 | 0.003595 | -0.802876 | 0.621033 |
| 15478 | 1.477571 | 1.228497 | 0.419694 | -0.263553 | -0.166734 | -0.044729 | 0.861603 | -1.352827 |
| 15479 | 0.817486 | -1.964414 | 1.121799 | -0.015848 | 0.897926 | 0.028507 | 1.104729 | -1.102971 |
15480 rows × 8 columns
get_score(LinearRegression(), X_train, X_test, y_train, y_test)
fitting :
LinearRegression()
X_train:(15480, 8) , X_test:(5160, 8) , y_train:(15480,) , y_test:(5160,)
0.5951538103198968
Pour une régression linéaire non. Expliquer pourquoi.
Mais c’est toujours mieux de le faire. Expliquer pourquoi.
Cross validation
wikipedia
Cross-validation,[1][2][3] sometimes called rotation estimation[4][5][6] or out-of-sample testing, is any of various similar model validation techniques for assessing how the results of a statistical analysis will generalize to an independent data set. It is mainly used in settings where the goal is prediction, and one wants to estimate how accurately a predictive model will perform in practice. In a prediction problem, a model is usually given a dataset of known data on which training is run (training dataset), and a dataset of unknown data (or first seen data) against which the model is tested (called the validation dataset or testing set).[7][8] The goal of cross-validation is to test the model’s ability to predict new data that was not used in estimating it, in order to flag problems like overfitting or selection bias[9] and to give an insight on how the model will generalize to an independent dataset (i.e., an unknown dataset, for instance from a real problem).

from sklearn.model_selection import cross_val_score
from sklearn.model_selection import KFold
CV parametre = nombre de folds
results = cross_val_score(LinearRegression(), X, y, cv=3)
display(results, results.mean(), results.std())
array([0.55502126, 0.58837838, 0.58544641])
0.5762820158960853
0.015081199273597358
results = cross_val_score(LinearRegression(), X, y, cv=5)
display(results, results.mean(), results.std())
array([0.54866323, 0.46820691, 0.55078434, 0.53698703, 0.66051406])
0.5530311140279233
0.06169160140952192
Attention à randomly select les données !
random_indexes = np.random.choice(range(0,np.size(X, axis=0)),size=np.size(X, axis=0),replace=False)
results = cross_val_score(LinearRegression(),
X[random_indexes,:],
y[random_indexes],
cv=5)
display(results, results.mean(), results.std())
array([0.60599314, 0.60012143, 0.60743432, 0.60345929, 0.59470724])
0.602343086362268
0.004554809079823222
mieux :
results = cross_val_score(LinearRegression(), X, y, cv=KFold(shuffle=True, n_splits=5))
display(results, results.mean(), results.std())
array([0.60468889, 0.59824467, 0.57829859, 0.63738733, 0.59901735])
0.6035273665776618
0.01914463194628335
def multiple_cross_val_scores(algorithme, X, y):
import numpy as np
results=dict()
for kfold in range(3,100, 20):
score = cross_val_score(algorithme, X, y, cv = KFold(shuffle=True, n_splits=kfold), scoring='r2')
results[kfold] = score.mean(), score.std()
return results
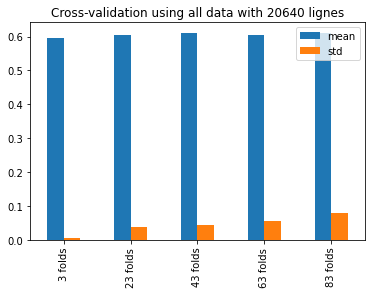
from sklearn.tree import DecisionTreeRegressor
import pandas as pd
test = multiple_cross_val_scores(DecisionTreeRegressor(),X, y)
test = pd.DataFrame(test, index=["mean", "std"]).T
test
| mean | std | |
|---|---|---|
| 3 | 0.596333 | 0.006556 |
| 23 | 0.605437 | 0.037804 |
| 43 | 0.610825 | 0.042940 |
| 63 | 0.606054 | 0.055790 |
| 83 | 0.611114 | 0.080461 |
new_index = [str(x) + " folds" for x in test.index]
test.index = new_index
test.plot(kind='bar', title='Cross-validation using all data with {} lignes'.format(X.shape[0]))
<AxesSubplot:title={'center':'Cross-validation using all data with 20640 lignes'}>
There are cases where the computational definition of R2 can yield negative values, depending on the definition used. This can arise when the predictions that are being compared to the corresponding outcomes have not been derived from a model-fitting procedure using those data. Even if a model-fitting procedure has been used, R2 may still be negative, for example when linear regression is conducted without including an intercept, or when a non-linear function is used to fit the data. In cases where negative values arise, the mean of the data provides a better fit to the outcomes than do the fitted function values, according to this particular criterion.
The constant minimizing the squared error is the mean. Since you are doing cross validation with left out data, it can happen that the mean of your test set is wildly different from the mean of your training set
R² = 1 - RSS / TSS, where RSS is the residual sum of squares ∑(y - f(x))² and TSS is the total sum of squares ∑(y - mean(y))². Now for R² ≥ -1, it is required that RSS/TSS ≤ 2, but it’s easy to construct a model and dataset for which this is not true:
**Inspect shuffling first ! If data is sorted at first !!! **
Decision Tree Regressor
from sklearn.tree import DecisionTreeRegressor
algorithme = DecisionTreeRegressor()
algorithme.fit(X_train, y_train)
score = algorithme.score(X_test, y_test)
performances[algorithme] = score
Criteria used for splitting
** Credits ** : © Adele Cutler
Image("td4_ressources/img_DecisionTreesSplitting_Criteria_ADELE-CUTLER-Ovronnaz_Switzerland.png", width=400)

Image("td4_ressources/img_gini index equation cart.png", retina=True)

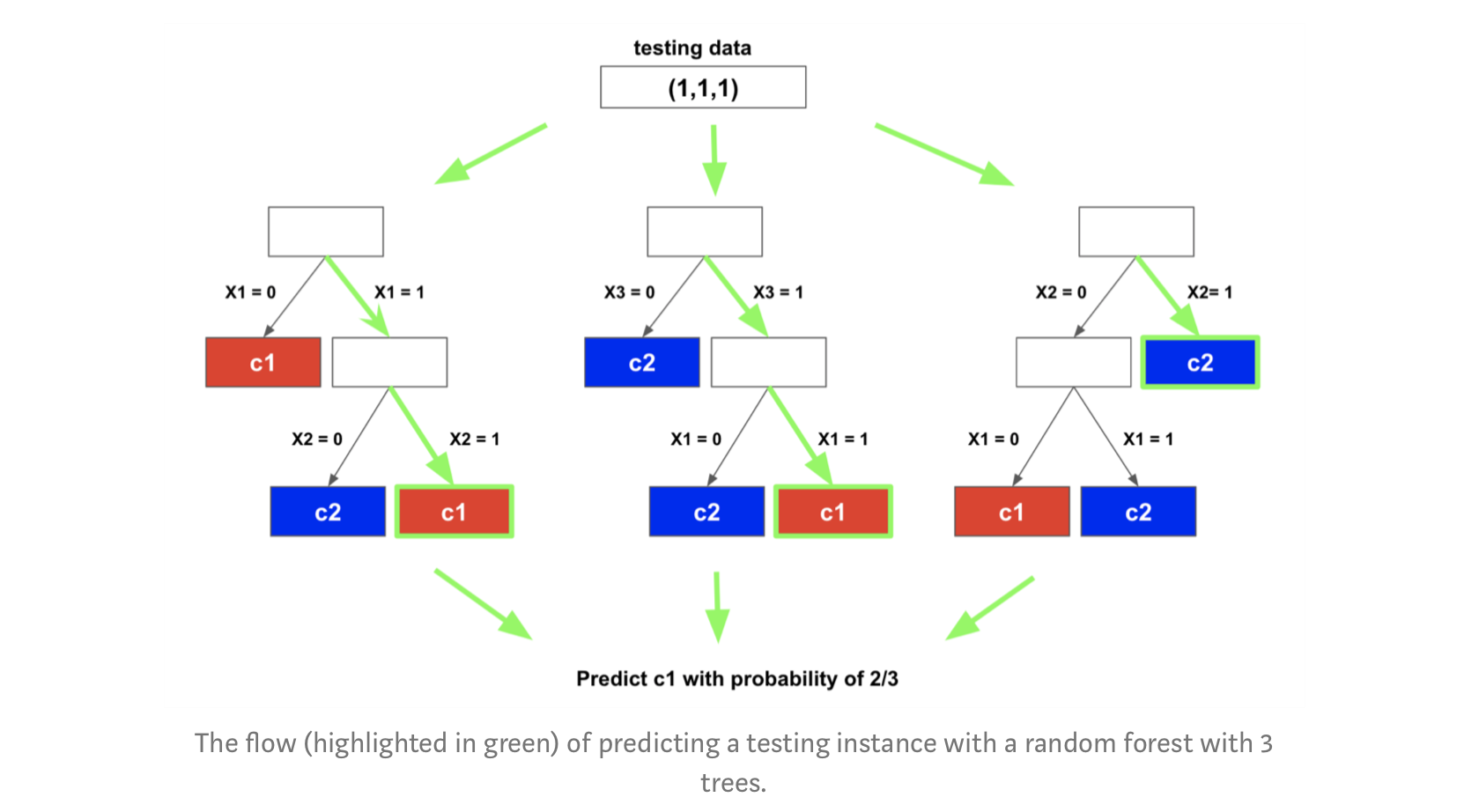
Random Forest example
interesting article introducing RandomForest & talking about intrees and RRF (regularized Random Forest): https://towardsdatascience.com/random-forest-3a55c3aca46d
** CREDITS : ** © Houtao_Deng_Medium
Image("td4_ressources/img_random_forest_bagging_Houtao_Deng_Medium.png", retina=True)

Image("td4_ressources/img_random_forest_testing_Houtao_Deng_Medium.png",retina=True)
from sklearn.ensemble import RandomForestRegressor
hyperparametres = { 'n_estimators':30 }
algorithme = RandomForestRegressor(**hyperparametres)
score = get_score(algorithme, X_train, X_test, y_train, y_test)
performances[algorithme] = score
fitting :
RandomForestRegressor(n_estimators=30)
X_train:(15480, 8) , X_test:(5160, 8) , y_train:(15480,) , y_test:(5160,)
hyperparametres = {"n_estimators" : 30, "max_features" : 3, "max_depth" : 50,}
algorithme = RandomForestRegressor(**hyperparametres)
score = get_score(algorithme, X_train, X_test, y_train, y_test)
performances[algorithme] = score
fitting :
RandomForestRegressor(max_depth=50, max_features=3, n_estimators=30)
X_train:(15480, 8) , X_test:(5160, 8) , y_train:(15480,) , y_test:(5160,)
ExtraTreesRegressor
from sklearn.ensemble import ExtraTreesRegressor
algorithme = ExtraTreesRegressor()
score = get_score(algorithme, X_train, X_test, y_train, y_test)
performances[algorithme] = score
fitting :
ExtraTreesRegressor()
X_train:(15480, 8) , X_test:(5160, 8) , y_train:(15480,) , y_test:(5160,)
utiliser n_jobs = -1 c’est mieux pour paralléliser quand on a plusieurs CPUs
SVR
from sklearn import svm
algorithme = svm.SVR(kernel='linear')
score = get_score(algorithme, X_train, X_test, y_train, y_test)
performances[algorithme] = score
print(score)
fitting :
SVR(kernel='linear')
X_train:(15480, 8) , X_test:(5160, 8) , y_train:(15480,) , y_test:(5160,)
0.22396975043473788
catboost
installation : !pip install catboost
from catboost import CatBoostRegressor
#algorithme = CatBoostRegressor(task_type="CPU")
#modele = algorithme.fit(X_train, y_train)
#score = algorithme.score(X_test, y_test)
#performances['catboost'] = score
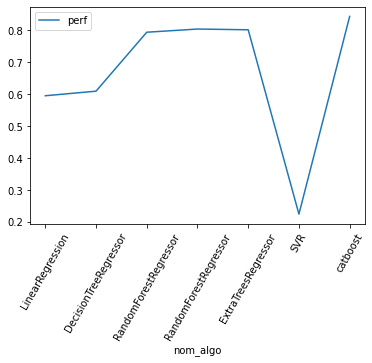
Simple visualisation des performances des différents algos
from collections import OrderedDict
dico_ordonne = OrderedDict(performances)
import pandas as pd
df = pd.DataFrame()
df["perf"] = dico_ordonne.values()
df["algo"] = dico_ordonne.keys()
df['nom_algo'] = df.algo.apply(lambda algo: str(algo).split('(')[0])
df.set_index('nom_algo', inplace=True)
df
/Users/lucbertin/.pyenv/versions/3.8.4/lib/python3.8/site-packages/numpy/core/_asarray.py:83: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
return array(a, dtype, copy=False, order=order)
| perf | algo | |
|---|---|---|
| nom_algo | ||
| LinearRegression | 0.595154 | LinearRegression() |
| DecisionTreeRegressor | 0.609499 | DecisionTreeRegressor() |
| RandomForestRegressor | 0.794347 | (DecisionTreeRegressor(max_features='auto', ra... |
| RandomForestRegressor | 0.804353 | (DecisionTreeRegressor(max_depth=50, max_featu... |
| ExtraTreesRegressor | 0.802039 | (ExtraTreeRegressor(random_state=1365029830), ... |
| SVR | 0.223970 | SVR(kernel='linear') |
| catboost | 0.843861 | catboost |
df[["perf"]].plot(kind='line', rot=60)
/Users/lucbertin/.pyenv/versions/3.8.4/lib/python3.8/site-packages/pandas/plotting/_matplotlib/core.py:1235: UserWarning: FixedFormatter should only be used together with FixedLocator
ax.set_xticklabels(xticklabels)
<AxesSubplot:xlabel='nom_algo'>
Aller au delà des hyperparamètres par défaut d’un modèle avec GridSearch
mieux d’utiliser n_jobs=-1 si plusieurs CPU pour paralléliser
Par défaut scikit-learn optimise les hyperparamètres tout en faisant une cross-validation. Sans celle-ci, c’est comme si le modèle optimisait ses coefficients sur la base d’apprentissage et ses hyperparamètres sur la base de test. De ce fait, toutes les données servent à optimiser un paramètre. La cross-validation limite en vérifiant la stabilité de l’apprentissage sur plusieurs découpages. On peut également découper en train / test / validation mais cela réduit d’autant le nombre de données pour apprendre.

Stackoverflow :
- All estimators in scikit where name ends with CV perform cross-validation. But you need to keep a separate test set for measuring the performance.
-
So you need to split your whole data to train and test and then forget about this test data for a while.
-
you will then pass this train data only to grid-search. GridSearch will split this train data further into train and test to tune the hyper-parameters passed to it. And finally fit the model on the whole initial training data with best found parameters.
-
Now you need to test this model on the test data you kept aside since the beginning. This will give you the near real world performance of model.
-
If you use the whole data into GridSearchCV, then there would be leakage of test data into parameter tuning and then the final model may not perform that well on newer unseen data.
from sklearn.model_selection import GridSearchCV
param_grid = {
'C' : np.linspace(0, 2, 10),
'gamma' : np.linspace(0, 2, 10)
}
grid = GridSearchCV(estimator=svm.SVR(),
param_grid=param_grid,
n_jobs=-1, cv=3, verbose=2)
ON ENTRAINE TOUJOURS LA GRILLE SUR LES DONNÉES D’ENTRAINEMENT !
grid.fit(X_train, y_train)
Fitting 3 folds for each of 100 candidates, totalling 300 fits
[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers.
[Parallel(n_jobs=-1)]: Done 25 tasks | elapsed: 1.6s
[Parallel(n_jobs=-1)]: Done 146 tasks | elapsed: 1.8min
[Parallel(n_jobs=-1)]: Done 300 out of 300 | elapsed: 5.2min finished
GridSearchCV(cv=3, estimator=SVR(), n_jobs=-1,
param_grid={'C': array([0. , 0.22222222, 0.44444444, 0.66666667, 0.88888889,
1.11111111, 1.33333333, 1.55555556, 1.77777778, 2. ]),
'gamma': array([0. , 0.22222222, 0.44444444, 0.66666667, 0.88888889,
1.11111111, 1.33333333, 1.55555556, 1.77777778, 2. ])},
verbose=2)
grid.cv_results_
{'mean_fit_time': array([2.87985802e-03, 3.07774544e-03, 3.49060694e-03, 2.83010801e-03,
2.54456202e-03, 2.36543020e-03, 2.96545029e-03, 3.14235687e-03,
3.02155813e-03, 3.10770671e-03, 4.35576518e+00, 5.45484789e+00,
5.33367936e+00, 5.08848143e+00, 5.11562395e+00, 4.93779731e+00,
4.91950901e+00, 5.02251569e+00, 5.07332786e+00, 5.24234764e+00,
3.71944729e+00, 5.53809182e+00, 5.72629245e+00, 5.48424172e+00,
5.61390662e+00, 6.21719495e+00, 6.61741455e+00, 6.58587146e+00,
6.17991837e+00, 6.43122490e+00, 4.15628123e+00, 5.49778763e+00,
5.55532972e+00, 5.82066313e+00, 6.00262809e+00, 6.07418243e+00,
6.31064606e+00, 6.41253972e+00, 6.76197767e+00, 7.19659233e+00,
4.11235499e+00, 5.60772665e+00, 5.92431696e+00, 6.16026799e+00,
6.48453363e+00, 6.71778830e+00, 6.82982937e+00, 7.30440140e+00,
7.63539052e+00, 7.89080628e+00, 3.90299853e+00, 5.95283906e+00,
6.32891870e+00, 6.68975941e+00, 7.01873430e+00, 7.41231783e+00,
7.84972676e+00, 8.32050602e+00, 8.49486796e+00, 8.66785638e+00,
3.87383556e+00, 5.91185093e+00, 6.61977267e+00, 7.17416008e+00,
7.70533657e+00, 7.98054099e+00, 8.38457656e+00, 8.90599338e+00,
9.21024982e+00, 9.78037429e+00, 3.85815088e+00, 6.25255768e+00,
6.95319104e+00, 7.59571107e+00, 8.28248064e+00, 8.57521605e+00,
9.13775206e+00, 9.74492041e+00, 1.02877928e+01, 1.07412132e+01,
3.86747773e+00, 6.58728067e+00, 7.41942898e+00, 8.11039710e+00,
9.01299262e+00, 9.49792027e+00, 9.89260801e+00, 1.54700281e+01,
2.64791640e+01, 2.70012914e+01, 4.19392085e+00, 6.72964390e+00,
7.76192323e+00, 8.80016200e+00, 9.86484130e+00, 1.05392163e+01,
1.10950196e+01, 1.14811863e+01, 1.12226790e+01, 9.87271778e+00]),
'std_fit_time': array([4.39120726e-04, 2.24039728e-04, 9.63629388e-04, 5.90233025e-04,
1.33952112e-04, 1.10682443e-04, 7.03725572e-04, 3.15952807e-04,
2.73406020e-04, 5.61604071e-04, 1.63486172e-02, 3.26892255e-02,
2.73474682e-01, 6.90403288e-02, 4.69917135e-02, 1.49403524e-01,
4.09500232e-02, 5.23185631e-02, 1.05207282e-01, 2.62526440e-02,
2.51185519e-02, 1.06445907e-01, 8.80014112e-02, 1.80576546e-01,
6.87593425e-02, 3.27420235e-02, 9.12644778e-02, 2.19233555e-01,
1.04023510e-01, 1.37735138e-01, 2.61240380e-01, 1.96230545e-01,
7.89759439e-02, 1.42985779e-02, 5.63498214e-02, 7.93775708e-02,
8.79950991e-02, 4.57558612e-02, 1.18140755e-01, 6.72603398e-02,
7.24628915e-02, 9.07270446e-02, 4.18443213e-02, 4.06271432e-02,
5.80198112e-02, 2.32368490e-02, 3.99548839e-02, 2.09543041e-02,
1.26502040e-01, 6.33546798e-02, 6.81969674e-02, 2.94051615e-02,
2.22950688e-02, 3.13332423e-02, 1.07354708e-01, 9.23337871e-02,
1.40262337e-01, 1.58560063e-01, 1.68726720e-02, 3.96816594e-02,
5.09282620e-02, 7.84815051e-02, 3.53948353e-02, 7.09583547e-02,
1.77196662e-01, 1.26913378e-01, 1.41470424e-01, 1.82113570e-01,
8.88552235e-02, 1.78381116e-01, 2.21484579e-02, 7.96942744e-02,
2.29605918e-02, 4.88893654e-02, 1.85853928e-02, 3.38966890e-02,
9.39823653e-02, 3.24714322e-02, 9.99877188e-02, 2.45509036e-01,
4.17044472e-02, 1.40062292e-02, 3.59729488e-02, 1.11045260e-01,
2.61532775e-02, 4.40995246e-02, 8.98449264e-02, 7.14027014e+00,
2.29746566e-01, 2.59416562e-01, 3.42676328e-02, 1.23958128e-01,
1.53038796e-01, 1.53760285e-01, 1.50391748e-02, 2.27918371e-02,
8.33621341e-02, 9.23326454e-03, 4.49305649e-01, 3.77896267e-01]),
'mean_score_time': array([0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
1.01334174, 1.39820019, 1.38140059, 1.38459293, 1.33943232,
1.34464304, 1.35476192, 1.36010774, 1.40606324, 1.49319267,
1.14655471, 1.5387489 , 1.38927015, 1.51753855, 1.65721162,
1.76165215, 1.50650183, 1.46471723, 1.55877535, 1.47708575,
1.12892572, 1.42128094, 1.42207662, 1.41378133, 1.42802533,
1.43166773, 1.42867708, 1.49164494, 1.63885371, 1.47642366,
1.04644529, 1.45029195, 1.38384875, 1.41731866, 1.40839863,
1.42921901, 1.42967232, 1.53262091, 1.51914954, 1.48684541,
1.04018919, 1.44831729, 1.39343667, 1.45557785, 1.41621463,
1.49535179, 1.43779111, 1.45611699, 1.46412587, 1.47920791,
1.03665392, 1.45309464, 1.42944964, 1.41378482, 1.3948199 ,
1.47603122, 1.4938031 , 1.4521277 , 1.48234471, 1.50318392,
1.05117671, 1.43348948, 1.42842285, 1.38882923, 1.42496634,
1.43919929, 1.47427758, 1.517459 , 1.48970262, 1.52956994,
1.05095037, 1.45296311, 1.45929162, 1.45250424, 1.44710008,
1.52260264, 1.4304297 , 6.66711227, 1.52382278, 1.52635519,
1.14289053, 1.44785571, 1.46046607, 1.46218475, 1.51698263,
1.51476916, 1.51054168, 1.46357505, 1.088557 , 0.81571333]),
'std_score_time': array([0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 9.00251796e-03, 4.75081373e-03,
8.14321463e-03, 4.93630370e-02, 1.01232671e-02, 1.24946931e-02,
2.53942545e-03, 2.43800006e-02, 2.30741952e-02, 2.53171208e-02,
2.44355808e-01, 2.88933494e-02, 1.98356648e-02, 1.28159998e-01,
3.58460830e-02, 3.98945383e-02, 1.57162358e-02, 2.68805308e-02,
1.68951467e-01, 3.55994691e-02, 9.39728080e-02, 2.37984539e-02,
1.55776607e-02, 1.31444478e-02, 2.26583323e-02, 7.47645314e-03,
5.64192456e-03, 4.41705367e-02, 1.71337106e-02, 6.25483878e-03,
1.22493320e-02, 2.59833053e-02, 9.25330534e-03, 2.11577944e-02,
1.65744892e-02, 7.77049759e-03, 1.01647613e-02, 6.56510468e-03,
5.30196345e-02, 4.48029742e-02, 1.99824705e-02, 3.27092097e-02,
2.20782211e-02, 1.14184596e-02, 2.25439165e-02, 9.52065400e-02,
5.53638073e-02, 1.00272988e-02, 2.75561257e-02, 6.51788108e-03,
1.34685479e-02, 1.53695876e-02, 1.64823381e-02, 3.52290862e-02,
9.49808503e-03, 1.54476588e-02, 2.68600702e-02, 2.60255336e-02,
9.37510511e-03, 1.76539821e-02, 5.10355420e-03, 2.77033717e-02,
1.04915173e-02, 2.15024769e-02, 9.31004694e-03, 1.10498854e-02,
1.06521243e-02, 5.29320796e-02, 1.06273821e-02, 2.12794663e-02,
1.08798859e-02, 4.65557245e-03, 1.00061232e-02, 5.14273985e-02,
9.36883777e-03, 7.31403699e-02, 1.01462077e-02, 7.00596557e+00,
2.10140152e-02, 2.03599772e-02, 1.01891002e-01, 5.20204475e-03,
2.84988438e-02, 1.54056191e-02, 8.68434921e-03, 3.62373004e-02,
3.27369714e-02, 6.46564053e-02, 1.92458941e-01, 3.40385330e-02]),
'param_C': masked_array(data=[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
0.2222222222222222, 0.2222222222222222,
0.2222222222222222, 0.2222222222222222,
0.2222222222222222, 0.2222222222222222,
0.2222222222222222, 0.2222222222222222,
0.2222222222222222, 0.2222222222222222,
0.4444444444444444, 0.4444444444444444,
0.4444444444444444, 0.4444444444444444,
0.4444444444444444, 0.4444444444444444,
0.4444444444444444, 0.4444444444444444,
0.4444444444444444, 0.4444444444444444,
0.6666666666666666, 0.6666666666666666,
0.6666666666666666, 0.6666666666666666,
0.6666666666666666, 0.6666666666666666,
0.6666666666666666, 0.6666666666666666,
0.6666666666666666, 0.6666666666666666,
0.8888888888888888, 0.8888888888888888,
0.8888888888888888, 0.8888888888888888,
0.8888888888888888, 0.8888888888888888,
0.8888888888888888, 0.8888888888888888,
0.8888888888888888, 0.8888888888888888,
1.1111111111111112, 1.1111111111111112,
1.1111111111111112, 1.1111111111111112,
1.1111111111111112, 1.1111111111111112,
1.1111111111111112, 1.1111111111111112,
1.1111111111111112, 1.1111111111111112,
1.3333333333333333, 1.3333333333333333,
1.3333333333333333, 1.3333333333333333,
1.3333333333333333, 1.3333333333333333,
1.3333333333333333, 1.3333333333333333,
1.3333333333333333, 1.3333333333333333,
1.5555555555555554, 1.5555555555555554,
1.5555555555555554, 1.5555555555555554,
1.5555555555555554, 1.5555555555555554,
1.5555555555555554, 1.5555555555555554,
1.5555555555555554, 1.5555555555555554,
1.7777777777777777, 1.7777777777777777,
1.7777777777777777, 1.7777777777777777,
1.7777777777777777, 1.7777777777777777,
1.7777777777777777, 1.7777777777777777,
1.7777777777777777, 1.7777777777777777, 2.0, 2.0, 2.0,
2.0, 2.0, 2.0, 2.0, 2.0, 2.0, 2.0],
mask=[False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False],
fill_value='?',
dtype=object),
'param_gamma': masked_array(data=[0.0, 0.2222222222222222, 0.4444444444444444,
0.6666666666666666, 0.8888888888888888,
1.1111111111111112, 1.3333333333333333,
1.5555555555555554, 1.7777777777777777, 2.0, 0.0,
0.2222222222222222, 0.4444444444444444,
0.6666666666666666, 0.8888888888888888,
1.1111111111111112, 1.3333333333333333,
1.5555555555555554, 1.7777777777777777, 2.0, 0.0,
0.2222222222222222, 0.4444444444444444,
0.6666666666666666, 0.8888888888888888,
1.1111111111111112, 1.3333333333333333,
1.5555555555555554, 1.7777777777777777, 2.0, 0.0,
0.2222222222222222, 0.4444444444444444,
0.6666666666666666, 0.8888888888888888,
1.1111111111111112, 1.3333333333333333,
1.5555555555555554, 1.7777777777777777, 2.0, 0.0,
0.2222222222222222, 0.4444444444444444,
0.6666666666666666, 0.8888888888888888,
1.1111111111111112, 1.3333333333333333,
1.5555555555555554, 1.7777777777777777, 2.0, 0.0,
0.2222222222222222, 0.4444444444444444,
0.6666666666666666, 0.8888888888888888,
1.1111111111111112, 1.3333333333333333,
1.5555555555555554, 1.7777777777777777, 2.0, 0.0,
0.2222222222222222, 0.4444444444444444,
0.6666666666666666, 0.8888888888888888,
1.1111111111111112, 1.3333333333333333,
1.5555555555555554, 1.7777777777777777, 2.0, 0.0,
0.2222222222222222, 0.4444444444444444,
0.6666666666666666, 0.8888888888888888,
1.1111111111111112, 1.3333333333333333,
1.5555555555555554, 1.7777777777777777, 2.0, 0.0,
0.2222222222222222, 0.4444444444444444,
0.6666666666666666, 0.8888888888888888,
1.1111111111111112, 1.3333333333333333,
1.5555555555555554, 1.7777777777777777, 2.0, 0.0,
0.2222222222222222, 0.4444444444444444,
0.6666666666666666, 0.8888888888888888,
1.1111111111111112, 1.3333333333333333,
1.5555555555555554, 1.7777777777777777, 2.0],
mask=[False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False],
fill_value='?',
dtype=object),
'params': [{'C': 0.0, 'gamma': 0.0},
{'C': 0.0, 'gamma': 0.2222222222222222},
{'C': 0.0, 'gamma': 0.4444444444444444},
{'C': 0.0, 'gamma': 0.6666666666666666},
{'C': 0.0, 'gamma': 0.8888888888888888},
{'C': 0.0, 'gamma': 1.1111111111111112},
{'C': 0.0, 'gamma': 1.3333333333333333},
{'C': 0.0, 'gamma': 1.5555555555555554},
{'C': 0.0, 'gamma': 1.7777777777777777},
{'C': 0.0, 'gamma': 2.0},
{'C': 0.2222222222222222, 'gamma': 0.0},
{'C': 0.2222222222222222, 'gamma': 0.2222222222222222},
{'C': 0.2222222222222222, 'gamma': 0.4444444444444444},
{'C': 0.2222222222222222, 'gamma': 0.6666666666666666},
{'C': 0.2222222222222222, 'gamma': 0.8888888888888888},
{'C': 0.2222222222222222, 'gamma': 1.1111111111111112},
{'C': 0.2222222222222222, 'gamma': 1.3333333333333333},
{'C': 0.2222222222222222, 'gamma': 1.5555555555555554},
{'C': 0.2222222222222222, 'gamma': 1.7777777777777777},
{'C': 0.2222222222222222, 'gamma': 2.0},
{'C': 0.4444444444444444, 'gamma': 0.0},
{'C': 0.4444444444444444, 'gamma': 0.2222222222222222},
{'C': 0.4444444444444444, 'gamma': 0.4444444444444444},
{'C': 0.4444444444444444, 'gamma': 0.6666666666666666},
{'C': 0.4444444444444444, 'gamma': 0.8888888888888888},
{'C': 0.4444444444444444, 'gamma': 1.1111111111111112},
{'C': 0.4444444444444444, 'gamma': 1.3333333333333333},
{'C': 0.4444444444444444, 'gamma': 1.5555555555555554},
{'C': 0.4444444444444444, 'gamma': 1.7777777777777777},
{'C': 0.4444444444444444, 'gamma': 2.0},
{'C': 0.6666666666666666, 'gamma': 0.0},
{'C': 0.6666666666666666, 'gamma': 0.2222222222222222},
{'C': 0.6666666666666666, 'gamma': 0.4444444444444444},
{'C': 0.6666666666666666, 'gamma': 0.6666666666666666},
{'C': 0.6666666666666666, 'gamma': 0.8888888888888888},
{'C': 0.6666666666666666, 'gamma': 1.1111111111111112},
{'C': 0.6666666666666666, 'gamma': 1.3333333333333333},
{'C': 0.6666666666666666, 'gamma': 1.5555555555555554},
{'C': 0.6666666666666666, 'gamma': 1.7777777777777777},
{'C': 0.6666666666666666, 'gamma': 2.0},
{'C': 0.8888888888888888, 'gamma': 0.0},
{'C': 0.8888888888888888, 'gamma': 0.2222222222222222},
{'C': 0.8888888888888888, 'gamma': 0.4444444444444444},
{'C': 0.8888888888888888, 'gamma': 0.6666666666666666},
{'C': 0.8888888888888888, 'gamma': 0.8888888888888888},
{'C': 0.8888888888888888, 'gamma': 1.1111111111111112},
{'C': 0.8888888888888888, 'gamma': 1.3333333333333333},
{'C': 0.8888888888888888, 'gamma': 1.5555555555555554},
{'C': 0.8888888888888888, 'gamma': 1.7777777777777777},
{'C': 0.8888888888888888, 'gamma': 2.0},
{'C': 1.1111111111111112, 'gamma': 0.0},
{'C': 1.1111111111111112, 'gamma': 0.2222222222222222},
{'C': 1.1111111111111112, 'gamma': 0.4444444444444444},
{'C': 1.1111111111111112, 'gamma': 0.6666666666666666},
{'C': 1.1111111111111112, 'gamma': 0.8888888888888888},
{'C': 1.1111111111111112, 'gamma': 1.1111111111111112},
{'C': 1.1111111111111112, 'gamma': 1.3333333333333333},
{'C': 1.1111111111111112, 'gamma': 1.5555555555555554},
{'C': 1.1111111111111112, 'gamma': 1.7777777777777777},
{'C': 1.1111111111111112, 'gamma': 2.0},
{'C': 1.3333333333333333, 'gamma': 0.0},
{'C': 1.3333333333333333, 'gamma': 0.2222222222222222},
{'C': 1.3333333333333333, 'gamma': 0.4444444444444444},
{'C': 1.3333333333333333, 'gamma': 0.6666666666666666},
{'C': 1.3333333333333333, 'gamma': 0.8888888888888888},
{'C': 1.3333333333333333, 'gamma': 1.1111111111111112},
{'C': 1.3333333333333333, 'gamma': 1.3333333333333333},
{'C': 1.3333333333333333, 'gamma': 1.5555555555555554},
{'C': 1.3333333333333333, 'gamma': 1.7777777777777777},
{'C': 1.3333333333333333, 'gamma': 2.0},
{'C': 1.5555555555555554, 'gamma': 0.0},
{'C': 1.5555555555555554, 'gamma': 0.2222222222222222},
{'C': 1.5555555555555554, 'gamma': 0.4444444444444444},
{'C': 1.5555555555555554, 'gamma': 0.6666666666666666},
{'C': 1.5555555555555554, 'gamma': 0.8888888888888888},
{'C': 1.5555555555555554, 'gamma': 1.1111111111111112},
{'C': 1.5555555555555554, 'gamma': 1.3333333333333333},
{'C': 1.5555555555555554, 'gamma': 1.5555555555555554},
{'C': 1.5555555555555554, 'gamma': 1.7777777777777777},
{'C': 1.5555555555555554, 'gamma': 2.0},
{'C': 1.7777777777777777, 'gamma': 0.0},
{'C': 1.7777777777777777, 'gamma': 0.2222222222222222},
{'C': 1.7777777777777777, 'gamma': 0.4444444444444444},
{'C': 1.7777777777777777, 'gamma': 0.6666666666666666},
{'C': 1.7777777777777777, 'gamma': 0.8888888888888888},
{'C': 1.7777777777777777, 'gamma': 1.1111111111111112},
{'C': 1.7777777777777777, 'gamma': 1.3333333333333333},
{'C': 1.7777777777777777, 'gamma': 1.5555555555555554},
{'C': 1.7777777777777777, 'gamma': 1.7777777777777777},
{'C': 1.7777777777777777, 'gamma': 2.0},
{'C': 2.0, 'gamma': 0.0},
{'C': 2.0, 'gamma': 0.2222222222222222},
{'C': 2.0, 'gamma': 0.4444444444444444},
{'C': 2.0, 'gamma': 0.6666666666666666},
{'C': 2.0, 'gamma': 0.8888888888888888},
{'C': 2.0, 'gamma': 1.1111111111111112},
{'C': 2.0, 'gamma': 1.3333333333333333},
{'C': 2.0, 'gamma': 1.5555555555555554},
{'C': 2.0, 'gamma': 1.7777777777777777},
{'C': 2.0, 'gamma': 2.0}],
'split0_test_score': array([ nan, nan, nan, nan, nan,
nan, nan, nan, nan, nan,
-0.06196089, 0.73214466, 0.73373369, 0.72516523, 0.71306186,
0.6972207 , 0.67927592, 0.65960967, 0.63845234, 0.61735647,
-0.06196089, 0.74619528, 0.75232431, 0.74832296, 0.74104045,
0.73164661, 0.72104823, 0.70876707, 0.69596002, 0.68261156,
-0.06196089, 0.75232544, 0.76005406, 0.7581677 , 0.75220469,
0.74498036, 0.73632244, 0.72637335, 0.7155938 , 0.70475805,
-0.06196089, 0.75592446, 0.76376342, 0.76324036, 0.75897055,
0.75260532, 0.74434339, 0.73531514, 0.72607746, 0.71637782,
-0.06196089, 0.75859488, 0.76645781, 0.76604825, 0.76284854,
0.75735062, 0.74933674, 0.74063068, 0.73220623, 0.72348988,
-0.06196089, 0.76061269, 0.76869185, 0.76818664, 0.76557441,
0.76045075, 0.75264389, 0.74457286, 0.73623336, 0.7276496 ,
-0.06196089, 0.76208374, 0.77025589, 0.76980038, 0.76728463,
0.76192291, 0.75464277, 0.74720407, 0.7388729 , 0.73016346,
-0.06196089, 0.76336257, 0.77131399, 0.7709491 , 0.76843843,
0.76284687, 0.7559595 , 0.74866539, 0.74045104, 0.73167153,
-0.06196089, 0.76462805, 0.77238269, 0.7717397 , 0.76915783,
0.76338819, 0.75677199, 0.74926808, 0.74115954, 0.73252807]),
'split1_test_score': array([ nan, nan, nan, nan, nan,
nan, nan, nan, nan, nan,
-0.05578486, 0.70925546, 0.71263101, 0.7037757 , 0.69064622,
0.67489018, 0.65776269, 0.64016744, 0.62245759, 0.60420855,
-0.05578486, 0.72546588, 0.73110582, 0.72697991, 0.71782805,
0.70685319, 0.69559409, 0.68334078, 0.67065372, 0.65797179,
-0.05578486, 0.73271519, 0.73941457, 0.73551699, 0.72984562,
0.72084543, 0.71092616, 0.70073946, 0.69054849, 0.67957028,
-0.05578486, 0.73732419, 0.74422664, 0.7409822 , 0.73546702,
0.72811885, 0.71938433, 0.71028719, 0.7008461 , 0.69059352,
-0.05578486, 0.7403644 , 0.74712832, 0.74470344, 0.73904543,
0.73205717, 0.72380531, 0.71588779, 0.70642145, 0.69655041,
-0.05578486, 0.74282525, 0.74903729, 0.74693045, 0.74155883,
0.73471893, 0.72714995, 0.71892022, 0.70969473, 0.70034312,
-0.05578486, 0.74492912, 0.75068064, 0.74863824, 0.74331287,
0.73647428, 0.72883023, 0.72075545, 0.71169396, 0.70261696,
-0.05578486, 0.74624316, 0.75196866, 0.75014681, 0.74463864,
0.73765643, 0.73006217, 0.721823 , 0.71264965, 0.70380148,
-0.05578486, 0.74761514, 0.75294949, 0.75108777, 0.74537865,
0.7381543 , 0.73073981, 0.72215701, 0.71304801, 0.70432754]),
'split2_test_score': array([ nan, nan, nan, nan, nan,
nan, nan, nan, nan, nan,
-0.05590591, 0.71773474, 0.71852433, 0.70932816, 0.69671346,
0.68172197, 0.66593495, 0.64859334, 0.63037894, 0.61125081,
-0.05590591, 0.73388366, 0.73758405, 0.73264726, 0.72515391,
0.71560025, 0.70481182, 0.69306925, 0.68085439, 0.66867798,
-0.05590591, 0.74139986, 0.74582273, 0.74175064, 0.73578324,
0.72885252, 0.72134432, 0.71187724, 0.7019901 , 0.69207519,
-0.05590591, 0.74597958, 0.75045729, 0.74732549, 0.7419171 ,
0.73580188, 0.7292087 , 0.72200491, 0.71382636, 0.70470107,
-0.05590591, 0.74967325, 0.75403464, 0.75128892, 0.74599468,
0.74018626, 0.73356409, 0.72701376, 0.71940712, 0.71101437,
-0.05590591, 0.75242534, 0.75628728, 0.75359455, 0.74862935,
0.74250641, 0.73668183, 0.73010753, 0.72245676, 0.7141626 ,
-0.05590591, 0.75433044, 0.75811465, 0.75559549, 0.75028379,
0.74419546, 0.73853598, 0.73192635, 0.72433274, 0.71606835,
-0.05590591, 0.75561149, 0.7595856 , 0.756823 , 0.75154613,
0.74573729, 0.73992929, 0.73309495, 0.72531518, 0.71711271,
-0.05590591, 0.75697522, 0.7605724 , 0.75774864, 0.75238758,
0.74670547, 0.74092649, 0.73375925, 0.7257051 , 0.71743617]),
'mean_test_score': array([ nan, nan, nan, nan, nan,
nan, nan, nan, nan, nan,
-0.05788389, 0.71971162, 0.72162967, 0.71275636, 0.70014051,
0.68461095, 0.66765785, 0.64945682, 0.63042962, 0.61093861,
-0.05788389, 0.73518161, 0.74033806, 0.73598338, 0.72800747,
0.71803335, 0.70715138, 0.69505903, 0.68248938, 0.66975378,
-0.05788389, 0.74214683, 0.74843045, 0.74514511, 0.73927785,
0.73155944, 0.72286431, 0.71299668, 0.70271079, 0.69213451,
-0.05788389, 0.74640941, 0.75281578, 0.75051602, 0.74545155,
0.73884201, 0.73097881, 0.72253574, 0.71358331, 0.7038908 ,
-0.05788389, 0.74954417, 0.75587359, 0.75401354, 0.74929621,
0.74319802, 0.73556871, 0.72784408, 0.71934493, 0.71035155,
-0.05788389, 0.75195443, 0.75800547, 0.75623721, 0.75192087,
0.74589203, 0.73882522, 0.7312002 , 0.72279495, 0.71405177,
-0.05788389, 0.7537811 , 0.75968372, 0.75801137, 0.7536271 ,
0.74753088, 0.74066966, 0.73329529, 0.72496654, 0.71628293,
-0.05788389, 0.75507241, 0.76095608, 0.7593063 , 0.7548744 ,
0.74874686, 0.74198365, 0.73452778, 0.72613862, 0.71752857,
-0.05788389, 0.75640614, 0.7619682 , 0.76019203, 0.75564135,
0.74941599, 0.74281276, 0.73506145, 0.72663755, 0.71809726]),
'std_test_score': array([ nan, nan, nan, nan, nan,
nan, nan, nan, nan, nan,
0.0028833 , 0.00944845, 0.00889056, 0.00906247, 0.00946657,
0.00934247, 0.00886683, 0.00796071, 0.00652993, 0.00537215,
0.0028833 , 0.00851237, 0.00887861, 0.00902695, 0.00968886,
0.01026705, 0.01052247, 0.01047516, 0.01039574, 0.01008786,
0.0028833 , 0.00802326, 0.00862544, 0.00955355, 0.00945661,
0.01003724, 0.01042354, 0.01049489, 0.0102374 , 0.01028295,
0.0028833 , 0.00759961, 0.00814835, 0.00936273, 0.00991542,
0.01022509, 0.01026608, 0.01022451, 0.01030209, 0.01054198,
0.0028833 , 0.00744312, 0.00799765, 0.00892442, 0.00999407,
0.01054333, 0.01051911, 0.01011829, 0.01052668, 0.01100798,
0.0028833 , 0.00726932, 0.0081154 , 0.00887672, 0.01007679,
0.0107743 , 0.01051763, 0.01050111, 0.01083699, 0.0111481 ,
0.0028833 , 0.00701411, 0.00806821, 0.00880668, 0.01006793,
0.0106537 , 0.01064538, 0.0108409 , 0.0111048 , 0.01124683,
0.0028833 , 0.00699936, 0.00795693, 0.00867214, 0.00999719,
0.01050183, 0.01067187, 0.0110051 , 0.0113648 , 0.0113817 ,
0.0028833 , 0.00695714, 0.00799473, 0.00860632, 0.00997673,
0.01047847, 0.01071096, 0.01110628, 0.01149541, 0.0115223 ]),
'rank_test_score': array([100, 98, 97, 96, 95, 94, 93, 92, 99, 91, 87, 58, 57,
67, 72, 75, 78, 79, 80, 81, 85, 42, 36, 40, 49, 61,
69, 73, 76, 77, 87, 33, 25, 30, 37, 46, 54, 66, 71,
74, 84, 27, 17, 20, 29, 38, 48, 56, 65, 70, 82, 21,
10, 14, 23, 31, 41, 50, 59, 68, 85, 18, 7, 9, 19,
28, 39, 47, 55, 64, 90, 15, 4, 6, 16, 26, 35, 45,
53, 63, 82, 12, 2, 5, 13, 24, 34, 44, 52, 62, 89,
8, 1, 3, 11, 22, 32, 43, 51, 60], dtype=int32)}
params = pd.DataFrame(grid.cv_results_.get("params"))
results = pd.DataFrame(
{k:v for k,v in grid.cv_results_.items()
if k.startswith('split')})
df_grid = pd.concat([params, results], axis=1)
df_grid
| C | gamma | split0_test_score | split1_test_score | split2_test_score | |
|---|---|---|---|---|---|
| 0 | 0.0 | 0.000000 | NaN | NaN | NaN |
| 1 | 0.0 | 0.222222 | NaN | NaN | NaN |
| 2 | 0.0 | 0.444444 | NaN | NaN | NaN |
| 3 | 0.0 | 0.666667 | NaN | NaN | NaN |
| 4 | 0.0 | 0.888889 | NaN | NaN | NaN |
| ... | ... | ... | ... | ... | ... |
| 95 | 2.0 | 1.111111 | 0.763388 | 0.738154 | 0.746705 |
| 96 | 2.0 | 1.333333 | 0.756772 | 0.730740 | 0.740926 |
| 97 | 2.0 | 1.555556 | 0.749268 | 0.722157 | 0.733759 |
| 98 | 2.0 | 1.777778 | 0.741160 | 0.713048 | 0.725705 |
| 99 | 2.0 | 2.000000 | 0.732528 | 0.704328 | 0.717436 |
100 rows × 5 columns
for name,group in df_grid.groupby(["C", "gamma"]):
group.plot()
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-1357-18bdb0668317> in <module>
----> 1 df_grid.groupby(["C", "gamma"]).stack().plot(kind="line")
~/.pyenv/versions/3.8.4/lib/python3.8/site-packages/pandas/core/groupby/groupby.py in __getattr__(self, attr)
701 return self[attr]
702
--> 703 raise AttributeError(
704 f"'{type(self).__name__}' object has no attribute '{attr}'"
705 )
AttributeError: 'DataFrameGroupBy' object has no attribute 'stack'
df_grid.set_index(["C", "gamma"]).stack().unstack(-1).T
| C | 0.222222 | ... | 2.000000 | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| gamma | 0.000000 | 0.222222 | 0.444444 | 0.666667 | 0.888889 | 1.111111 | 1.333333 | 1.555556 | 1.777778 | 2.000000 | ... | 0.000000 | 0.222222 | 0.444444 | 0.666667 | 0.888889 | 1.111111 | 1.333333 | 1.555556 | 1.777778 | 2.000000 |
| split0_test_score | -0.061961 | 0.732145 | 0.733734 | 0.725165 | 0.713062 | 0.697221 | 0.679276 | 0.659610 | 0.638452 | 0.617356 | ... | -0.061961 | 0.764628 | 0.772383 | 0.771740 | 0.769158 | 0.763388 | 0.756772 | 0.749268 | 0.741160 | 0.732528 |
| split1_test_score | -0.055785 | 0.709255 | 0.712631 | 0.703776 | 0.690646 | 0.674890 | 0.657763 | 0.640167 | 0.622458 | 0.604209 | ... | -0.055785 | 0.747615 | 0.752949 | 0.751088 | 0.745379 | 0.738154 | 0.730740 | 0.722157 | 0.713048 | 0.704328 |
| split2_test_score | -0.055906 | 0.717735 | 0.718524 | 0.709328 | 0.696713 | 0.681722 | 0.665935 | 0.648593 | 0.630379 | 0.611251 | ... | -0.055906 | 0.756975 | 0.760572 | 0.757749 | 0.752388 | 0.746705 | 0.740926 | 0.733759 | 0.725705 | 0.717436 |
3 rows × 90 columns
ax = df_grid.set_index(["C", "gamma"]).T.plot(kind="line", figsize=(10,4))
ax.set_ylim(0.6, 0.8)
ax.get_legend().remove()
plt.xticks(rotation=90)
/Users/lucbertin/.pyenv/versions/3.8.4/lib/python3.8/site-packages/pandas/plotting/_matplotlib/core.py:1235: UserWarning: FixedFormatter should only be used together with FixedLocator
ax.set_xticklabels(xticklabels)
(array([-0.25, 0. , 0.25, 0.5 , 0.75, 1. , 1.25, 1.5 , 1.75,
2. , 2.25]),
[Text(-0.25, 0, ''),
Text(0.0, 0, 'split0_test_score'),
Text(0.25, 0, ''),
Text(0.5, 0, ''),
Text(0.75, 0, ''),
Text(1.0, 0, 'split1_test_score'),
Text(1.25, 0, ''),
Text(1.5, 0, ''),
Text(1.75, 0, ''),
Text(2.0, 0, 'split2_test_score'),
Text(2.25, 0, '')])
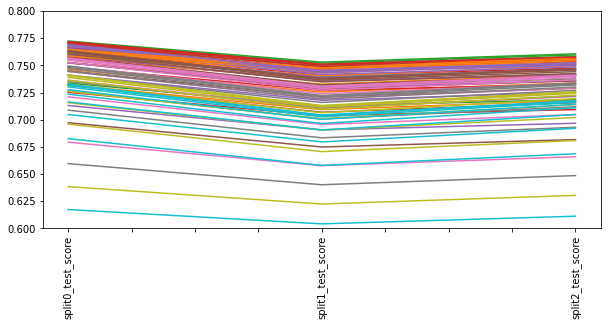
pivot = df_grid.pivot_table(index='C', columns='gamma').stack(level=1).apply(np.mean, axis=1)
sns.heatmap(pivot.unstack().iloc[:, 1:])
<AxesSubplot:xlabel='gamma', ylabel='C'>
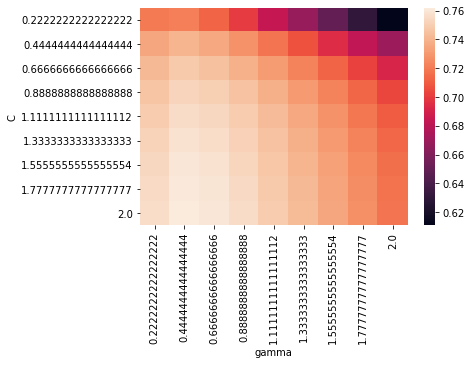
grid.best_params_
{'C': 2.0, 'gamma': 0.4444444444444444}
grid.best_estimator_
SVR(C=2.0, gamma=0.4444444444444444)
grid.best_score_
0.7619681962801373
on peut alors réutiliser ce best estimator en le réentrainant sur l’ensemble de X_train et pas un subset de X_train
model = svm.SVR(C=1.5, cache_size=200, coef0=0.0, degree=3, epsilon=0.1, gamma=0.1,
kernel='rbf', max_iter=-1, shrinking=True, tol=0.001, verbose=False)
model.fit(X_train, y_train)
SVR(C=1.5, gamma=0.1)
model.score(X_test, y_test)
0.726282532325518
performance proche du split
à tâton pour trouver le meilleur modèle
hyperparametres_possibles = {
'C' : [1.5, 2, 2.5],
'gamma' :[0.01, 0.05, 1]
}
grid = grid_search.GridSearchCV(estimator=svm.SVR(),
param_grid=hyperparametres_possibles,
n_jobs=-1)
grid.fit(X_train, y_train)
grid.best_score_
grid.best_params_
{'C': 2.5, 'gamma': 0.05}
hyperparametres_possibles = {
'C' : [2.5, 3, 3.5],
'gamma' :[0.01, 0.05, 1]
}
grid = grid_search.GridSearchCV(estimator=svm.SVR(),
param_grid=hyperparametres_possibles,
n_jobs=-1)
grid.fit(X_train, y_train)
grid.best_score_
grid.best_params_
{'C': 3.5, 'gamma': 0.05}
hyperparametres_possibles = {
'C' : [3.5, 4, 5, 6],
'gamma' :[0.01, 0.05, 1]
}
grid = grid_search.GridSearchCV(estimator=svm.SVR(),
param_grid=hyperparametres_possibles,
n_jobs=-1)
grid.fit(X_train, y_train)
grid.best_score_, grid.best_params_
(0.7501429622074626, {'C': 6, 'gamma': 0.05})
hyperparametres_possibles = {
'C' : [ 6, 8, 10],
'gamma' :[0.01, 0.05, 1]
}
grid = grid_search.GridSearchCV(estimator=svm.SVR(),
param_grid=hyperparametres_possibles,
n_jobs=-1)
grid.fit(X_train, y_train)
grid.best_score_, grid.best_params_
(0.7741648460590741, {'C': 10, 'gamma': 0.05})
hyperparametres_possibles = {
'C' : [ 10, 15, 20],
'gamma' :[0.01, 0.05, 1]
}
grid = grid_search.GridSearchCV(estimator=svm.SVR(),
param_grid=hyperparametres_possibles,
n_jobs=-1)
grid.fit(X_train, y_train)
grid.best_score_, grid.best_params_
(0.7872540631505356, {'C': 15, 'gamma': 0.05})
Assess model stability (Using Bootstrap)
from sklearn.utils import resample
resample(X, y, n_samples = 2, replace=True)
[array([[7.52601e+00, 0.00000e+00, 1.81000e+01, 0.00000e+00, 7.13000e-01,
6.41700e+00, 9.83000e+01, 2.18500e+00, 2.40000e+01, 6.66000e+02,
2.02000e+01, 3.04210e+02, 1.93100e+01],
[4.41780e-01, 0.00000e+00, 6.20000e+00, 0.00000e+00, 5.04000e-01,
6.55200e+00, 2.14000e+01, 3.37510e+00, 8.00000e+00, 3.07000e+02,
1.74000e+01, 3.80340e+02, 3.76000e+00]]), array([13. , 31.5])]
def Simulation(algorithme, X, y, nb_simulations=100):
from sklearn.model_selection import train_test_split
## where we store all scores from simulations
scores = []
for i in range(nb_simulations):
## Resample with replacement in all dataset
random_indexes = np.random.choice(range(np.size(X, axis=0)), size=np.size(X, axis=0),replace=True)
the_rest = [x for x in range(np.size(X, axis=0)) if x not in random_indexes]
## Split in Train, Test (0.75/0.25) and compute score
scores.append(get_score(algorithme,
X_train=X[random_indexes, :],
X_test =X[the_rest, :],
y_train=y[random_indexes],
y_test =y[the_rest],
display_options=False))
return scores
scores_decision_trees = Simulation(DecisionTreeRegressor(),X, y, nb_simulations=1000)
scores_rf = Simulation(RandomForestRegressor(),X, y, nb_simulations=1000)
scores_linear_regression_OLS = Simulation(LinearRegression(),X, y, nb_simulations=1000)
import seaborn as sns
fig, ax = plt.subplots(figsize=(12,4), nrows=1, ncols=1)
sns.distplot(scores_decision_trees, ax=ax)
sns.distplot(scores_rf, ax=ax)
sns.distplot(scores_linear_regression_OLS, ax=ax)
plt.legend(["Decision Tree Regressor", "Random Forest Regressor", "Linear Regressor"])
plt.title("Boostrap procedure to assess model stability")
#sns.distplot(scores_elasticnet, ax=ax)
/Users/lucbertin/anaconda3/lib/python3.6/site-packages/scipy/stats/stats.py:1713: FutureWarning: Using a non-tuple sequence for multidimensional indexing is deprecated; use `arr[tuple(seq)]` instead of `arr[seq]`. In the future this will be interpreted as an array index, `arr[np.array(seq)]`, which will result either in an error or a different result.
return np.add.reduce(sorted[indexer] * weights, axis=axis) / sumval
/Users/lucbertin/anaconda3/lib/python3.6/site-packages/matplotlib/axes/_axes.py:6462: UserWarning: The 'normed' kwarg is deprecated, and has been replaced by the 'density' kwarg.
warnings.warn("The 'normed' kwarg is deprecated, and has been "
/Users/lucbertin/anaconda3/lib/python3.6/site-packages/matplotlib/axes/_axes.py:6462: UserWarning: The 'normed' kwarg is deprecated, and has been replaced by the 'density' kwarg.
warnings.warn("The 'normed' kwarg is deprecated, and has been "
/Users/lucbertin/anaconda3/lib/python3.6/site-packages/matplotlib/axes/_axes.py:6462: UserWarning: The 'normed' kwarg is deprecated, and has been replaced by the 'density' kwarg.
warnings.warn("The 'normed' kwarg is deprecated, and has been "
Text(0.5,1,'Boostrap procedure to assess model stability')
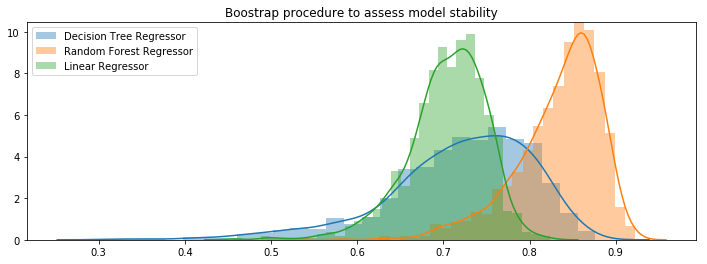
from sklearn.linear_model import ElasticNet
def grid_search_best_score(algorithme, hyperparametres):
from sklearn.grid_search import GridSearchCV
grid = GridSearchCV(algorithme, param_grid=hyperparametres, scoring='r2', n_jobs=-1)
grid.fit(X_train, y_train)
return grid.best_score_, grid.best_estimator_
hyperparametres = {'alpha':[1.0], 'l1_ratio':[0.5]}
grid_search_best_score(ElasticNet(), hyperparametres)
hyperparametres = {'alpha':np.linspace(0.1,0.9,50), 'l1_ratio':np.linspace(0.1,0.9,50)}
grid_search_best_score(ElasticNet(), hyperparametres)
hyperparametres = {'alpha':np.linspace(0.01,0.1,10), 'l1_ratio':np.linspace(0.01,0.1,10)}
grid_search_best_score(ElasticNet(), hyperparametres)
hyperparametres = {'alpha':np.linspace(0.025, 0.035,10), 'l1_ratio':[0.001]}
grid_search_best_score(ElasticNet(), hyperparametres)
np.mean(scores_decision_trees), np.mean(scores_rf)
np.std(scores_decision_trees), np.std(scores_rf)
Fin.
Annexes, nice ressources //

Image("td4_ressources/img_Ridge_Lasso_Regularization.png", retina=True)
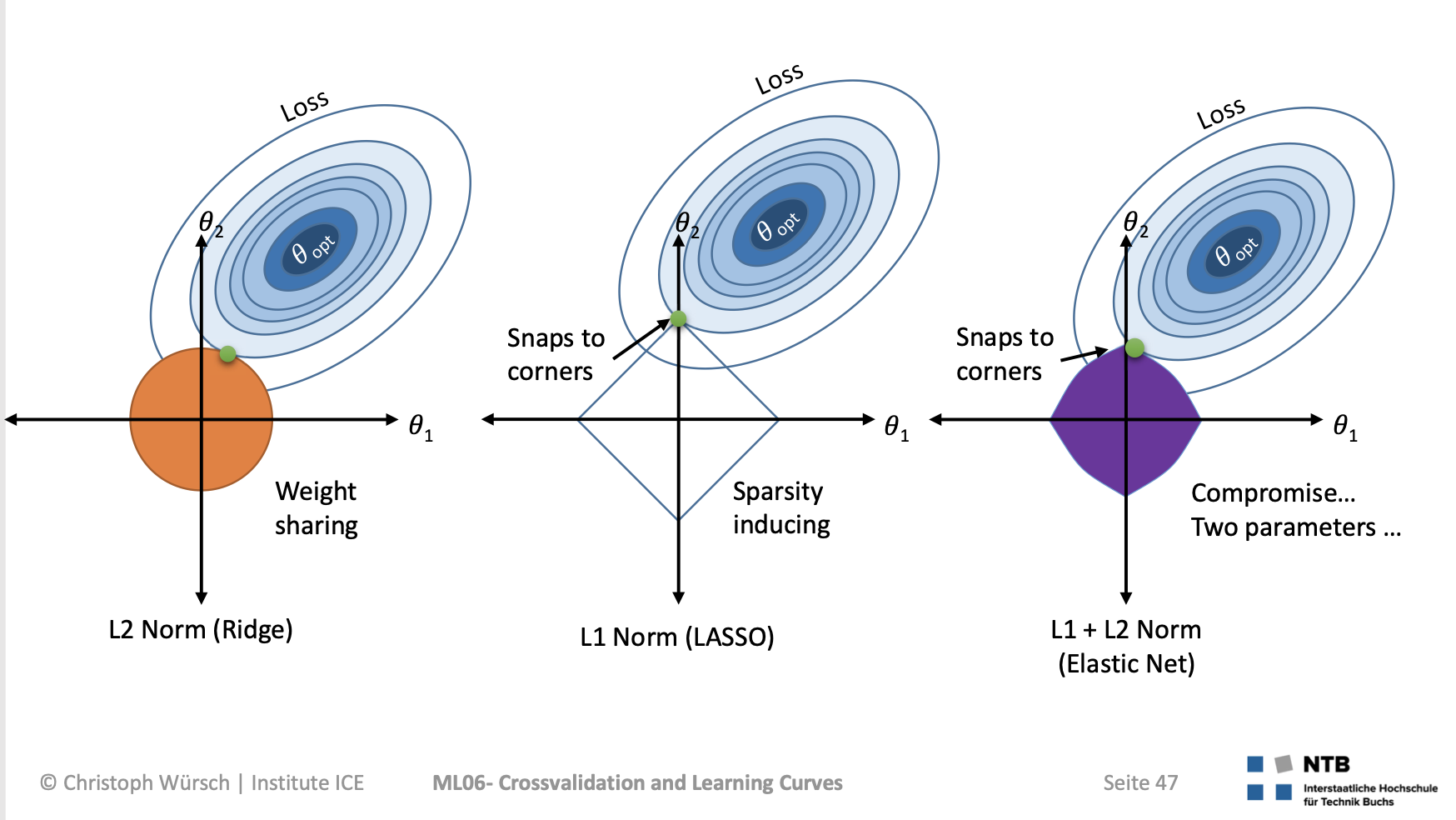

Image("td4_ressources/img_bootstrap_limit_0638.png", width=600)

** Credits: ** Stanford Edu